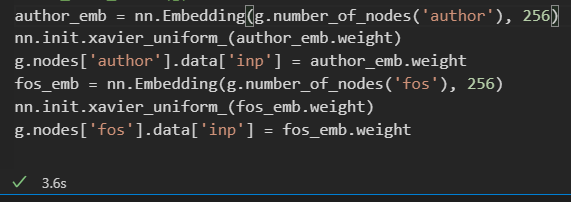
I am a newbie here, I build a heterograph for link prediction training. The graph doesnot have features, so I initialize features like this:
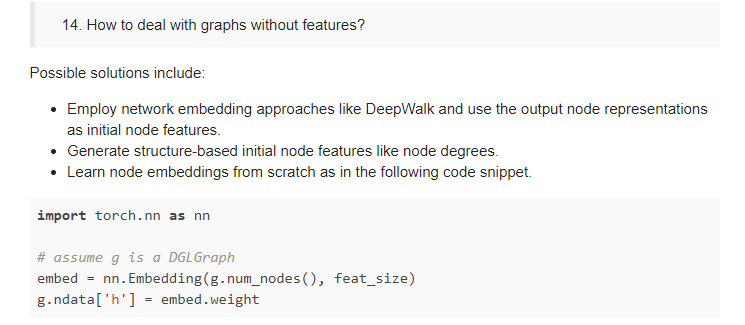
my question is will the input features being updated during train.
I print the g.ndata after training, but the value remains the same.
how to learn node features from scratch?
I use dataloader for minibatch training, I know the RGCN will output the node hidden states, should I copy the hidden states to the original graph? and how to copy this tensor to the oraginal graph?