
I build a simple GCN by DGL. However, it takes too much time to put the model to GPU.

Could someone help me? thanks first !
Hi,
I don’t think this is because of DGL. It seems a PyTorch problem. Does other script with PyTorch also take long time to call .cuda()?
Does this happen only for the first time or every time it is called?
Thank you. No, only model takes long time while data.to(device)(data is graphs of DGL)doesn’t take long time, so I think it may be the problem of message passing mechanism of the model in DGL?
Actually I haven’t load the model to GPU successfully since it takes too much time.(I wait about an hour but it have not done so I just terminate it). This phenomenon happen in every time I call.
Would you mind sharing a minimal script of code with us so that we can take a look?
Also could you help provide the information below? It would be helpful for us to investigate.
- DGL Version (e.g., 1.0):
- Backend Library & Version (e.g., PyTorch 0.4.1, MXNet/Gluon 1.3):
- OS (e.g., Linux):
- How you installed DGL (
conda,pip, source):- Build command you used (if compiling from source):
- Python version:
- CUDA/cuDNN version (if applicable):
- GPU models and configuration (e.g. V100):
- Any other relevant information:
Sure. The GCN that I defined is as follows.
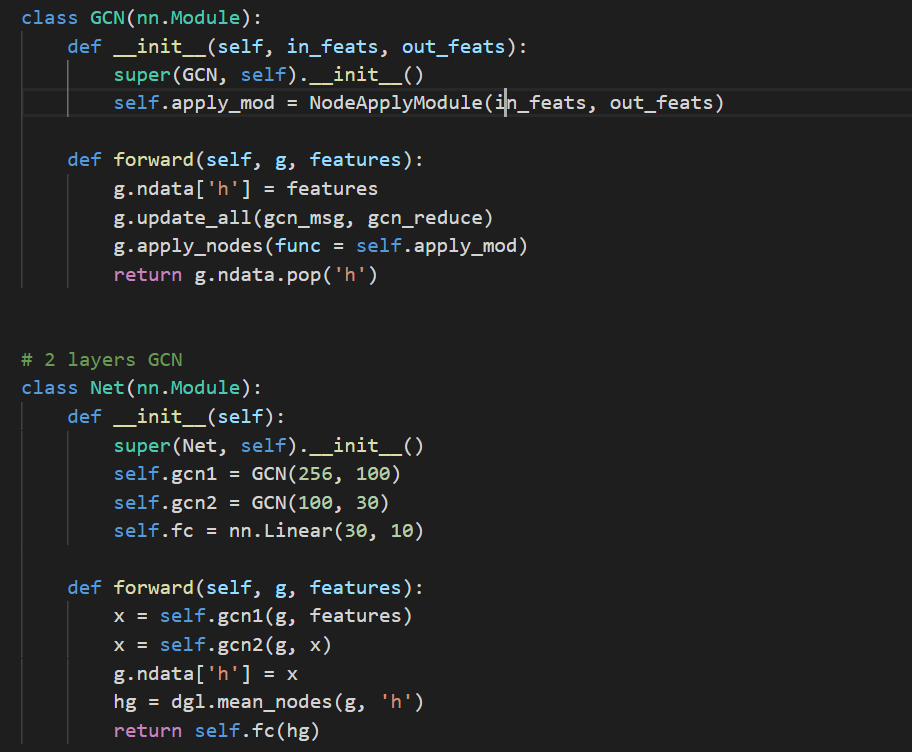
The message and reduce functions are
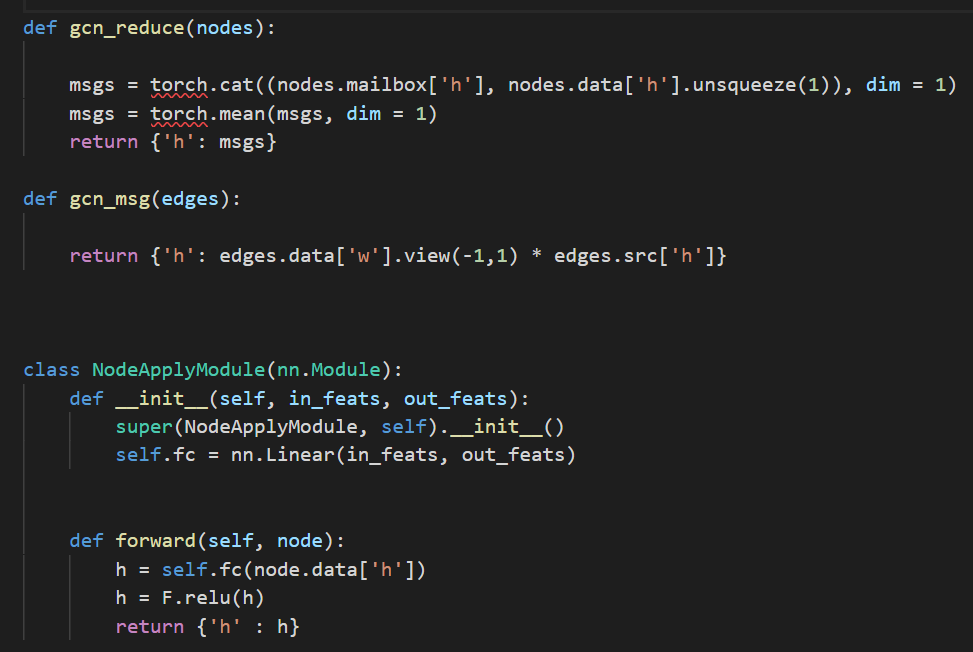
Then I just want to put this GCN to GPU:
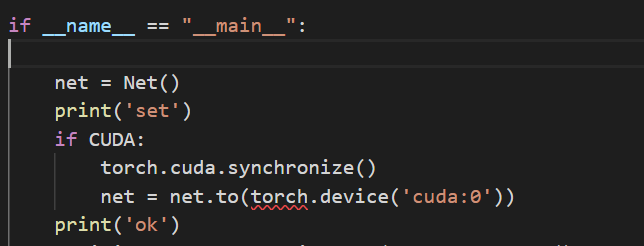
But it took me too much time so I just terminated the process.
Sure!
DGL version:may be v0.3? (I just use the command “conda install -c dglteam dgl-cuda9.0” to install according to the offical)
PyTorch 1.0.1. post2
OS ubuntu16.04
conda install -c dglteam dgl-cuda9.0
just use command “python xxx.py”
python 3.6.8
CUDA 0.9
sorry I don’t know GPU models and configuration(if really need, I’ll check it later)
Thank you!
@mkl I’ve made an initial attempt to run your code which seems to work fine on my machine. Where and how did you declare CUDA? Have you tried removing torch.cuda.synchronize()?
Really? CUDA is variate which is 1 or 0(1 means that I’ll try to use GPU.)
Yes I have tried removing torch.cuda.synchronize() but it doesn’t work as well.
Could you show me your entire code?
@mkl See below:
import dgl
import torch
import torch.nn as nn
import torch.nn.functional as F
class NodeApplyModule(nn.Module):
def __init__(self, in_feats, out_feats):
super(NodeApplyModule, self).__init__()
self.fc = nn.Linear(in_feats, out_feats)
def forward(self, nodes):
h = self.fc(nodes.data['h'])
h = F.relu(h)
return {'h': h}
def gcn_reduce(nodes):
msgs = torch.cat((nodes.mailbox['h'], nodes.data['h'].unsqueeze(1)), dim=1)
return {'h': torch.mean(msgs, dim=1)}
def gcn_msg(edges):
return {'h': edges.data['w'].view(-1, 1) * edges.src['h']}
class GCN(nn.Module):
def __init__(self, in_feats, out_feats):
super(GCN, self).__init__()
self.apply_mod = NodeApplyModule(in_feats, out_feats)
def forward(self, g, features):
g.ndata['h'] = features
g.update_all(gcn_msg, gcn_reduce)
g.apply_nodes(func=self.apply_mod)
return g.ndata.pop('h')
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.gcn1 = GCN(256, 100)
self.gcn2 = GCN(100, 30)
self.fc = nn.Linear(30, 10)
def forward(self, g, feats):
x = self.gcn1(g, feats)
x = self.gcn2(g, x)
g.ndata['h'] = x
hg = dgl.mean_nodes(g, 'h')
return self.fc(hg)
if __name__ == '__main__':
net = Net()
print('set')
torch.cuda.synchronize()
net = net.to('cuda:0')
print('ok')
I copy your entire code, but it still doesn’t work. Could you show your configurations?
CUDA version、DGL version and pytorch version. Thank you very much!
I’m using:
- CUDA: 9.0
- PyTorch: 1.1.0
- dgl: 0.3
Maybe you can first try running several dgl free PyTorch examples on GPU and see if this works.
Thank you very much. I update my pytorch version to 1.1.0 and the problem has been solved.
Besides, I use another machine with pytorch version 1.0.1 but cuda version 10, it also has no problem.
So I think PyTorch 1.0.1 with CUDA 0.9 may the main reason for this problem.
Thanks for all people that help me!
1 Like