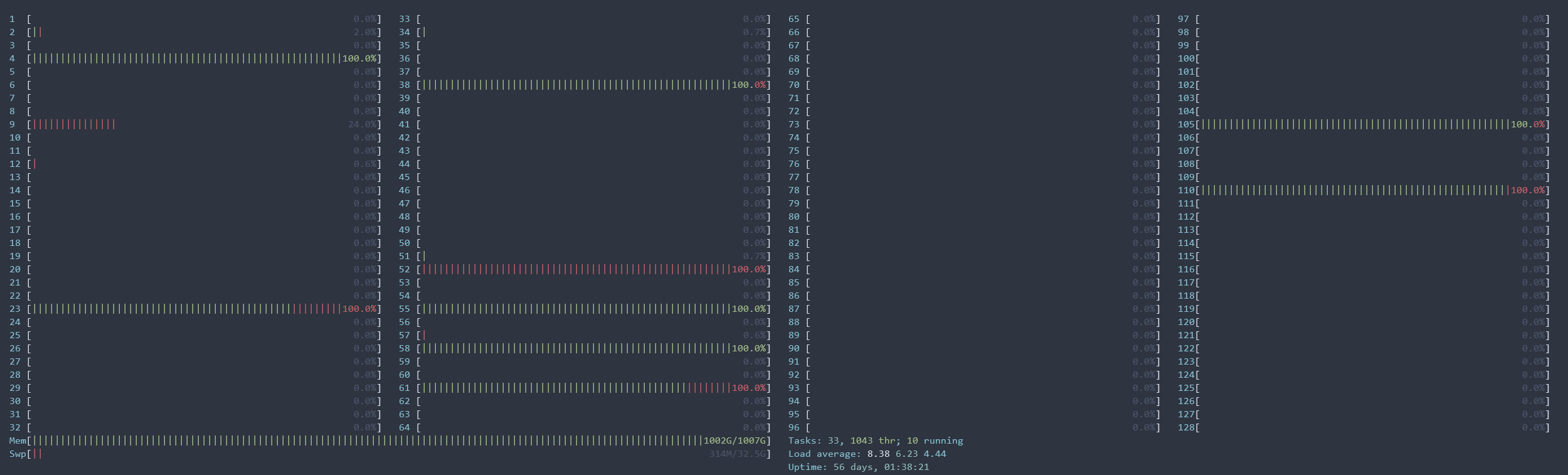
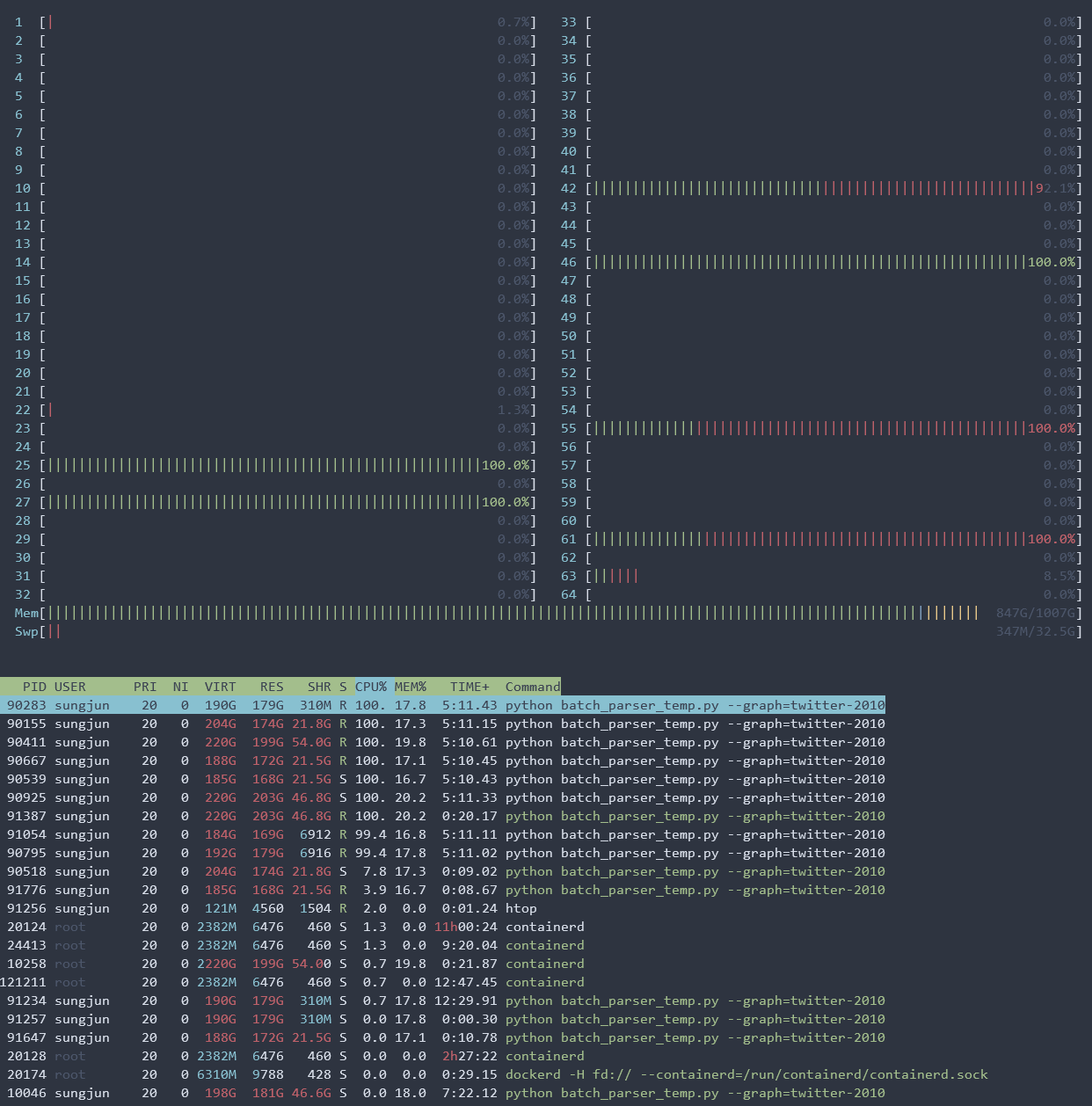
Here’s my test code.
Instantiating NodeDataLoader takes a large amount of memory
import argparse
import torch
#torch.multiprocessing.set_sharing_strategy('file_system')
import dgl
import numpy as np
import sys
sys.path.append('/home/sungjun/lab/pytorch/gnn/dataset_loader')
from TwitterDataset import TwitterDataset
from SinaweiboDataset import SinaweiboDataset
from FriendsterDataset import FriendsterDataset
from ogb.nodeproppred import DglNodePropPredDataset
def load_dataset(dataset_name):
if dataset_name.startswith('ogbn'):
ogbn_dataset_root = '/home/shared/gnn_dataset/ogbn/dataset'
return DglNodePropPredDataset(name = dataset_name,
root = ogbn_dataset_root)
elif dataset_name == 'twitter-2010':
return TwitterDataset()
elif dataset_name == 'friendster':
return FriendsterDataset()
elif dataset_name == 'sinaweibo':
return SinaweiboDataset()
else:
assert False
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-g', '--graph', type = str,
help = 'dataset', default = 'ogbn-products',
dest = "dataset")
parser.add_argument('-b', '--batch', type = int,
help = 'batch size', default = 2048,
dest = "batch")
args = parser.parse_args()
print("Start loading dataset")
dataset = load_dataset(dataset_name = args.dataset)
graph, label = dataset[0]
print("End loading dataset")
fanout_list = ['full']
num_layers = 4
for fanout in fanout_list:
print("Processing: {}".format(fanout))
if fanout == 'full':
sampler = dgl.dataloading.MultiLayerFullNeighborSampler(num_layers)
else:
sampler = dgl.dataloading.MultiLayerNeighborSampler([
int(nbr) for nbr in fanout.split(',')])
train_nids = dataset.get_idx_split()['train']
dataloader = dgl.dataloading.NodeDataLoader(
graph,
train_nids,
sampler,
batch_size = args.batch,
shuffle = True,
drop_last = True,
device = 'cpu',
num_workers = 8)
src_list = []
for step, (input_nodes, output_nodes, mfgs) in enumerate(dataloader):
for i, mfg in enumerate(mfgs):
g = dgl.block_to_graph(mfg)
#srcs = np.asarray(g.srcnodes['_N_src'].data[dgl.NID].to('cpu'))
srcs = np.asarray(g.srcnodes['_N_src'].data[dgl.NID])
src_list.append(srcs)
if step == 1:
break