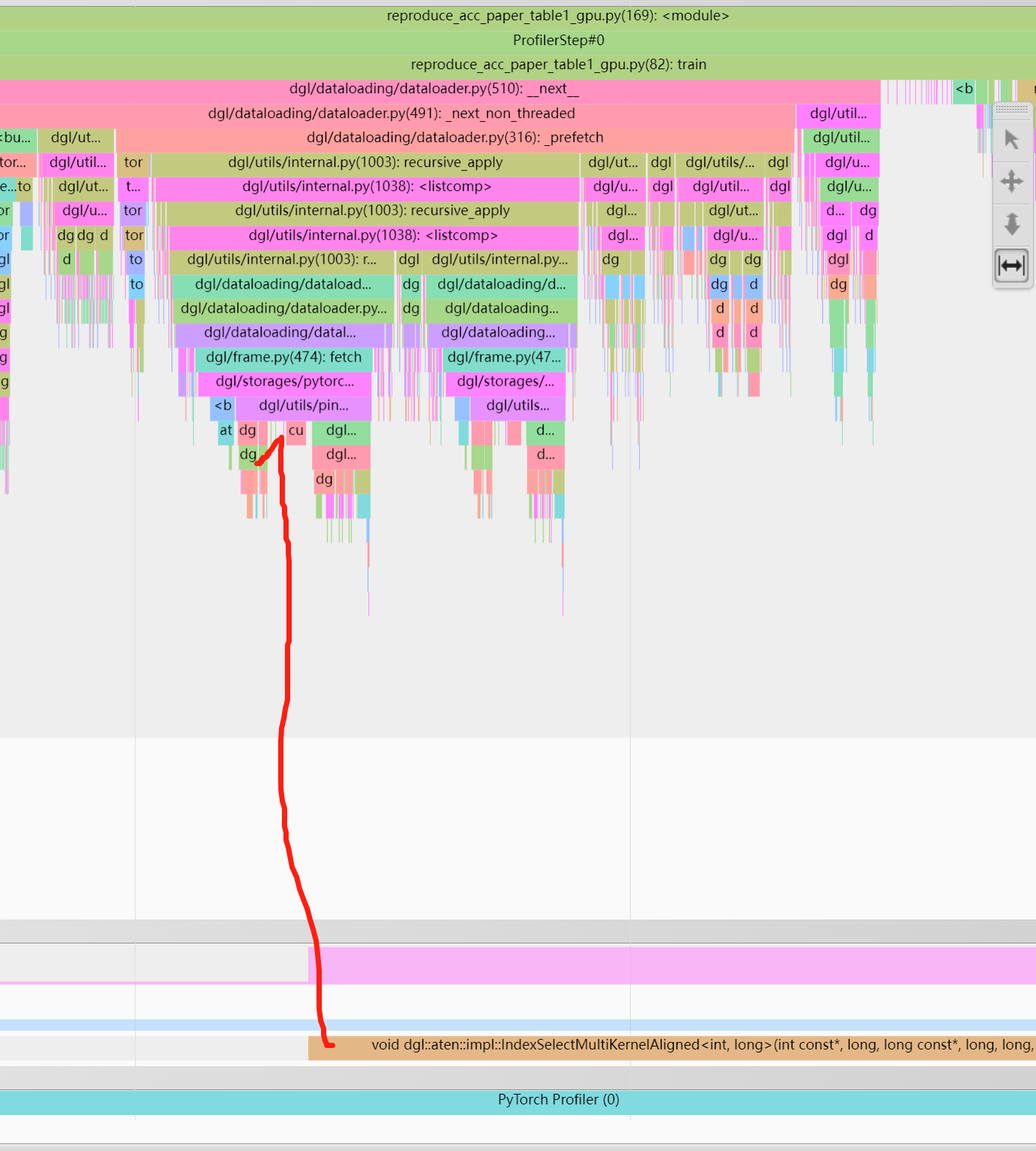
After looking at Training GNN with Neighbor Sampling for Node Classification and 6.8 Feature Prefetching, I am still confused on when features are moved from CPU memory to GPU memory when no prefetching is specified in the sampler.
6.8 Feature Prefetching suggests:
Accessing subgraph features will incur data fetching from the original graph immediately while prefetching ensures data to be available before getting from data loader.
Meanwhile, the L1_large_node_classification.py example used in the first link has the following line
What does “here” mean? My understanding is that there is some kind of “lazy” mechanism in play here, but when does the copy actually end up happening? I am interested in measuring the latency of the CPU-GPU copy.
Also, the DataLoader docs mention the device argument determines where the MFG is generated. Does the MFG in this context include features as well, meaning that features are already placed on the specified device (seemingly going against the lazy mechanism)? I am trying to understand the relation of this argument to the aforementioned CPU-GPU copy.
Thanks in advance.