
Currently, I am working on implementing GraphSage for an industrial node classification application. Here is a brief description of my scenario:
In my application, each node in the graph has around 21 features associated with it. However, not all of these features can be used directly due to the possibility of a Feature Leak problem. Therefore, I need to carefully select the features to be utilized in my implementation.
To make it simple, the demand is:
For each node, when aggregate its feature with the neighbor, we only need 3 features(selected from the 21 features) of its own and all 21 features for its neighbor, to form a updated embedding.
At first glance, it seems to be quiet simple, right? All you need to do is slicing(masking) the features like:
Change the original code below:
From the original code:
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
to my Own MaskedSAGEConv:
def sliced_rst(self, origin_tensor, feature_index_list) -> torch.Tensor:
...
# returns the sliced features
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
if is_first_layer == False:
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
# if first layer, slice the feature(which is totally wrong!)
sliced_features = self.sliced_rst(
h_self, self.feature_index_list)
self_feature_after_linear = self.fc_self_fl(sliced_features)
self_feature_after_linear)
sliced_rst = self_feature_after_linear + h_neigh
return self.activation(sliced_rst) if self.activation else sliced_rst
However, This impl wrongly comprehended the GraphSage. Since I initially think all I need to do was to pick(slice) the “self feature” when aggregating in “first layer”,(I used to think the aggregate process to be in->out but actually it is out->in ) but it is totally wrong. And let me clarify the issue with my comprehension for GraphSage and DGL now.
Actually, the SAGECONV follows a “First Sampling then aggregating” Pattern, like:
(image quote from 源码解析GraphSAGE原理与面试题汇总 - 知乎)
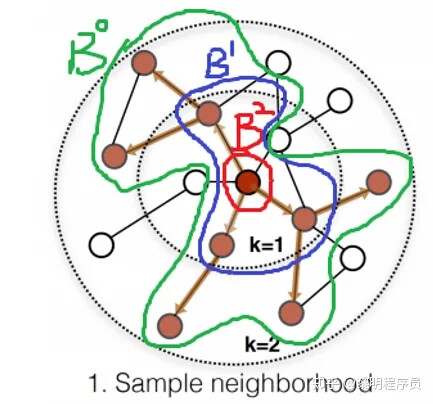
presented in the image, the B2 are the nodes in our “sampled batch”, and then we sample its 1 hop neighs B1 and 2 hops neighs B0, we use:
sampler = NeighborSampler(
[10, 10, 10], # fanout for [layer-0, layer-1, layer-2]
prefetch_node_feats=["feat"],
prefetch_labels=["label"],
)
g = dataset.graph
train_dataloader = dgl.dataloading.DataLoader(
g,
train_nid,
sampler,
batch_size=1024,
shuffle=True,
drop_last=False,
num_workers=4,
)
...
with tqdm.tqdm(train_loader) as tq:
for step, (input_nodes, output_nodes, blocks) in enumerate(tq):
inputs = blocks[0].srcdata['feat'].to(self.device)
labels = blocks[-1].dstdata['label'].to(self.device)
#
# for block in blocks:
# print("block.srcdata[feat]", block.srcdata['feat'])
logits = self.model(blocks, inputs)
and we can observed the sampled blocks are:
blocks [Block(num_src_nodes=1819, num_dst_nodes=1797, num_edges=824), Block(num_src_nodes=1797, num_dst_nodes=1688, num_edges=790), Block(num_src_nodes=1688, num_dst_nodes=1024, num_edges=664)]
block.shape 3
So from the outter to the inner, we have:
Src 1819 -- B2
Dest 1797 -- B2 -> B1
----------------------
Src 1797 -- B1
Dest 1688 -- B1->B0
----------------------
Src 1688 -- B0
Dest 1024 -- B0 and this is what we call batch size
After sampling, the we accordingly do the Conv process:
self.n_layers = n_layers
self.n_hidden = n_hidden
self.n_classes = n_classes
self.layers = nn.ModuleList()
self._feature_index_list = feature_index_list
# input layer
self.layers.append(MaskedSAGEConv(
in_feats * self.embeddings_dim,
n_hidden,
"mean",
feature_index_list=self._feature_index_list,
))
# hidden layers
for i in range(1, n_layers - 1):
self.layers.append(MaskedSAGEConv(
n_hidden,
n_hidden,
"mean",
feature_index_list=self._feature_index_list
))
# output layer
self.layers.append(MaskedSAGEConv(
n_hidden,
n_classes,
"mean",
feature_index_list=self._feature_index_list
))
...
def forward(self, blocks, in_feats):
h = self.embedding_all(in_feats)
h = h.double()
for i, (layer, block) in enumerate(zip(self.layers, blocks)):
if i == 0: # this is the wrong implementation!!!!!
h = layer(block, h, is_first_layer=True)
else:
h = layer(block, h)
# last layer does not need activation and dropout
if i != self.n_layers - 1:
h = self.activation(h)
h = self.dropout(h)
return h
you can simply regard the for-loop above as:
h = MaskedSAGEConv(block[0],h)
h = MaskedSAGEConv(block[1],h)
h = MaskedSAGEConv(block[2],h)
we back to the wrong impl of MaskedSAGEConv
def sliced_rst(self, origin_tensor, feature_index_list) -> torch.Tensor:
...
# returns the sliced features
def forward(self, graph, feat, is_first_layer: bool = False):
with graph.local_scope():
if isinstance(feat, tuple):
feat_src = self.feat_drop(feat[0])
feat_dst = self.feat_drop(feat[1])
else:
feat_src = feat_dst = self.feat_drop(feat)
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
msg_fn = fn.copy_u("h", "m")
h_self = feat_dst
lin_before_mp = self._in_src_feats > self._out_feats
# Message Passing
if self._aggre_type == "mean":
graph.srcdata["h"] = (
self.fc_neigh(feat_src) if lin_before_mp else feat_src
)
graph.update_all(msg_fn, fn.mean("m", "neigh"))
h_neigh = graph.dstdata["neigh"]
if not lin_before_mp:
h_neigh = self.fc_neigh(h_neigh)
if is_first_layer == False:
self_feature_after_linear = self.fc_self(h_self)
rst = self_feature_after_linear + h_neigh
return self.activation(rst) if self.activation else rst
# if first layer, slice the feature(which is totally wrong!)
sliced_features = self.sliced_rst(
h_self, self.feature_index_list)
self_feature_after_linear = self.fc_self_fl(sliced_features)
self_feature_after_linear)
sliced_rst = self_feature_after_linear + h_neigh
return self.activation(sliced_rst) if self.activation else sliced_rst
Here’s the key point
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
we inspect the feat_dst and feat_src for each layer, we will have
feat_src shape: torch.Size([1819, 168]) # 168 since 21feature each with 8 dim of embeddings
feat_dst shape: torch.Size([1797, 168])
h_self shape: torch.Size([1797, 168])
h_neigh shape: torch.Size([1797, 16]) # 16 is the hidden layer size in linear
sliced_features shape: torch.Size([1797, 24]) # which is wrong since I should not slice the 2-hop's node features, and 24 is because 3 features with 8 dims, returned by my impl of sliced_rst
self.fc_self_fl(sliced_features) shape: torch.Size([1797, 16]) # 16 since the
and for the following 2 layers:
it will also “conv” like:
(1797,16)->(1688,16)->(1024,2) # 1024 for batch size and 2 for binary classifications
So Here you may see the problem:
my demand is=> For each node, use its selected 3 features only, instead of all 21 features. And use all 21 features from its neighbor, to form a updated embedding.
And the fact is that I wrongly sliced the node, since the correct understanding is: The first layer are the nodes from 2-hop neighs, and the second layer are the nodes from 1-hop neighs, and the last layer are the nodes from the sampled batch.
However, after figuring it out, I found it is extremely difficult to mask(slice) features for each node, since
the
if graph.is_block:
feat_dst = feat_src[:graph.number_of_dst_nodes()]
# combo with the linear layer
self.fc_self_fl(sliced_features) shape: torch.Size([1797, 16])
since in the most inner layer, the dim is no longer 21*8, but 16, which is the hidden layer size in linear layer, and it is impossible to slice the features for each node.
Can anyone help me with this? Or do dgl have better wayz to access the features for each node in the sampled batch instead this kind of out->inner conv