
Sincerely thank you for reading my question and answer it! Thank you very much!
-
Background
- A traffic intersection with east, west, north and south four directions. The maximum queuing length of the four directions in one signal cycle are abstracted as nodes. The nodes are connected with each other, while the two nodes on the same line belong to the same signal group, which is described in the figure using the red lines.
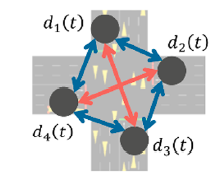
- In this case there exist two type edges and one type node.
- graph structure: 6 edges, 4 nodes and 1 type node, 2 type edges
- graph attribute: node features. Just as the queuing lengths belong to respective nodes, it should be treated as node features.
- The mission:
node embedding with the message-passing GNN
- A traffic intersection with east, west, north and south four directions. The maximum queuing length of the four directions in one signal cycle are abstracted as nodes. The nodes are connected with each other, while the two nodes on the same line belong to the same signal group, which is described in the figure using the red lines.
-
My Ideas
- There are two main questions confused me most:
-
initial input feature: the graph structure is invariable, while the features constantly changes each signal cycle as every cycle exists only one maximum queuing length for each direction.
But as I learned, the input graph is always only one. Variable is just the size of the graph input, through the technique of mini-batch or sampling. And it seems that I cannot train my RGCN with the changed different node features, since they are different graphs describing different signal cycle but definitely portray the same intersection which I need to get the node embeddings.
So how can I make the queuing length number value to be a node feature. And how to use the large amount of data to train the RGCN. It will help me a lot!
-
train part: Since the mission is just to embed the node. And the downstream task is as the input of reinforcement learning, it is different from traditional classification or prediction tasks.
In my opinion, it should adopt the unsupervised training method like the word2vec. But should I use the dot product to express the similarity of nodes? I think it can be used when the embedding feature representing can reflect the structure similarity.
-
- There are two main questions confused me most:
Your advice will be of great help to me! Sincerely thank you!