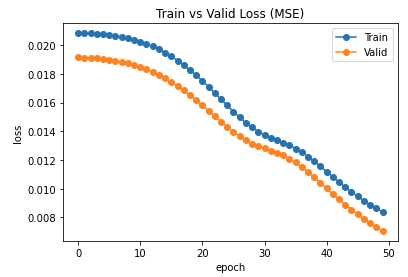
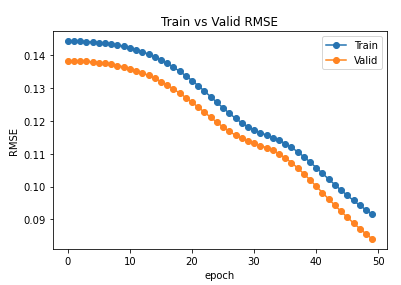
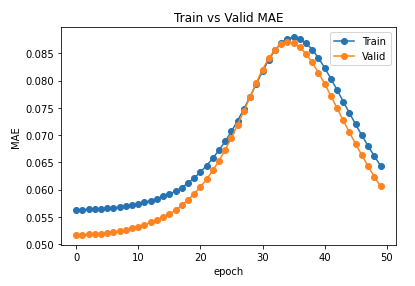
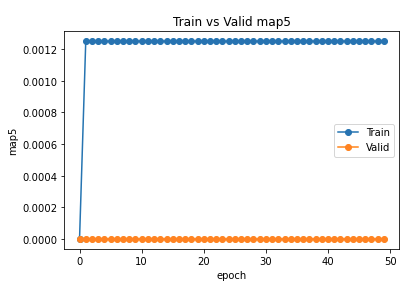
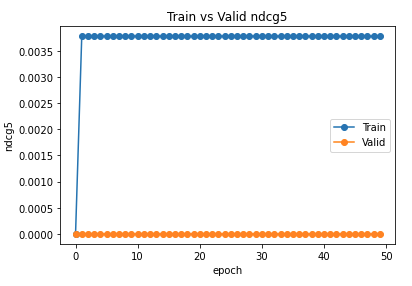
I am having strange empirical results. I am trying to solve edge regression problem on heterogenous graph. Here is info about the graph:
Graph(num_nodes={'query': 50, 'resource': 149},
num_edges={('query', 'relevant', 'resource'): 4286, ('resource', 'relevant-too', 'query'): 4286},
metagraph=[('query', 'resource', 'relevant'), ('resource', 'query', 'relevant-too')])
I am following the code provided in link
It is strange that NDCG and MAP are also not improving. Any suggestion please?
graph = dgl.heterograph({
('query', 'relevant', 'resource'): (query_src_torch, resource_dst_torch),
('resource', 'relevant-too', 'query'): (resource_dst_torch, query_src_torch)
})
graph.edges['relevant'].data['weight'] = relevant_torch
graph.edges['relevant-too'].data['weight'] = relevant_torch
graph.nodes['query'].data['features'] = query_features_torch
graph.nodes['resource'].data['features'] = resource_features_torch
nodes_features = {
'query': graph.nodes['query'].data['features'],
'resource': graph.nodes['resource'].data['features']
}
edge_weights = {
'relevant': {'edge_weight': graph.edata['weight'][('query', 'relevant', 'resource')]},
'relevant-too': {'edge_weight': graph.edata['weight'][('resource', 'relevant-too', 'query')]}
}
y_true = graph.edges['relevant'].data['weight']
for epoch in range(epochs):
model.train()
y_pred = model(graph, nodes_features, edge_weights, ('query', 'relevant', 'resource'))
loss = criterion(y_pred.view(len(y_true))[train_mask], y_true[train_mask])
opt.zero_grad()
loss.backward()
opt.step()
ranking_metrics = get_ranking_evaluation(dataset.query_resource_pairs, train_test_threshold, y_pred, True)
model.eval()
with torch.no_grad():
y_pred = model(graph, nodes_features, edge_weights, ('query', 'relevant', 'resource'))
loss = criterion(y_pred.view(len(y_true))[test_mask], y_true[test_mask])
ranking_metrics = get_ranking_evaluation(dataset.query_resource_pairs, train_test_threshold, y_pred, False)