
Hi all. When I profile the training process of Graphsage dgl/node_classification.py at master · dmlc/dgl · GitHub under the tensorboard.profiler. When use the uva and sample the subgraph on GPU, I find I am a little confused about dgl/rowwise_sampling.cu at aad3bd0484a1312e97942f60e2dd5e7197a14f3c · dmlc/dgl · GitHub(it was called in the next function in iter) this line of code in cuda, why I should copy the frame from GPU to CPU. (the ongoing process of sampling is done on GPU, so I am a little confused why we should copy it back to CPU and this process seems time-consuming), so can anyone helps me to let me know why this process is needed . so does this line of code dgl/cuda_to_block.cu at bcd37684268a919f25aa5b9eb88f4e59aca1e7b4 · dmlc/dgl · GitHub the to_block function called in next) I find it is time consuming on CPU time, and I guess we should preserve intermediate state in the second layer, so if this line of code and the former one I mentioned is used to save intermediate state?(can we skip these process of transfer data from GPU to CPU and just did all of the computing on GPU? ). The two process can be seen at the cudamemcpyasync in the picture below
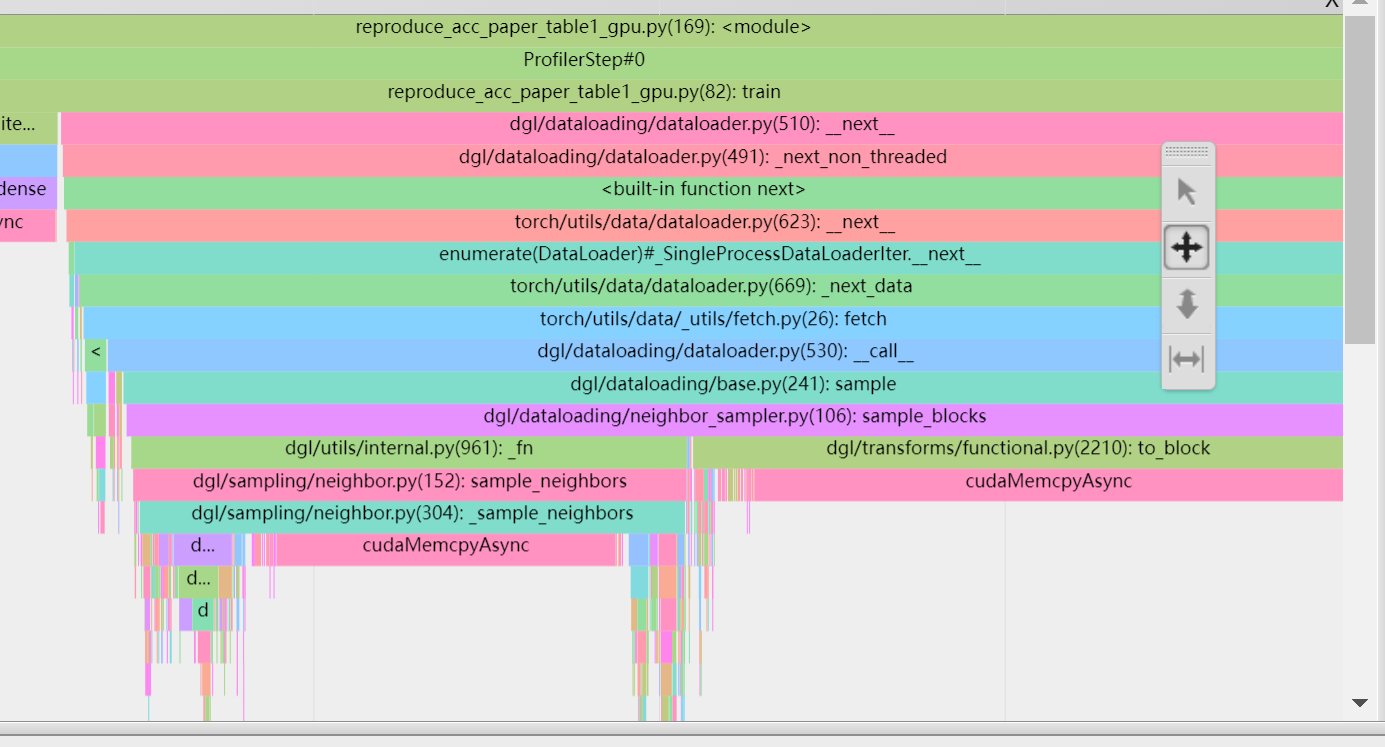
I see the same discussion happen in our slack channel. If possible, please move the discussion here for future reference.
OK I have moved the answer here, thank you for help!
Dominique LaSalle
This is to copy the size of the tensors for the nodes to the CPU, so that we know many unique src nodes there are. We need this for two reasons:
1., dlpack and subsequently DGL relies on the tensor shape being the CPU,
2., further kernel launches depend on this shape (e.g., to know how many threads to launch).
CUDA performs busy wait when waiting to synchronize, which is why you see the high CPU usage.
2
Dominique LaSalle
In this case we don’t need those size till later, so we could allocate pinned memory (but it would need to be from a pool rather than directly via the cuda API), and wait on a cuda event instead.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.