Hi guys, this is my first GNN project and I am hoping someone could kindly share some feedback on how I have chosen to frame my problem for a GNN.
Essentially, I am trying to predict horse races. I have 100k historical races where each race can have up to N runners. I have framed this problem as a graph classification problem. The objective is to, predict which horse is going to win a race by the starting gate of that horse. The output vector is of size N, for up to N runners in the race, or N starting gates. For now, I am ignoring trainers, owners and jockeys. As such, I have defined the following entities:
Nodes
- Horse (static info on a horse incl. colour, breed etc.)
- Race (info about a race such as weather, year, month, day of week, distance, track etc.)
Edges
- (Horse, Run, Race) (info about a horse running in a race PRIOR to the race occurring. Info such as age at race start, starting gate etc.)
- (Horse, Run Outcome, Race) (info about a horse run in a race AFTER the race occurring. Superset of Run with info such as finishing time, finishing position etc.)
- (Precedes, Race, Precedes) (edge to encode race chronology, measures number of days by which
race iprecedesrace i + 1.)
For a given race that I am trying to predict, I firstly get all the runners in that race via the pertinent incoming Run edges. I then get every historical race for each runner and for each of those races, get the corresponding competitor horses nodes to create a full picture of each horse’s history. For connections between all horses and historical races, I use Run Outcome edges. This way, the interactions between the runners and the current race I am predicting on does not include future information (relative to said race.)
I am not sure if this is the best representation of this data universe. Perhaps I shouldn’t sequentially connect races by the Precedes edge and instead, connect them all to the current race being predicted. I am also unsure if framing this as a graph classification problem is correct. Currently, all features are encoded as a matrix features attribute on each node/edge rather than flattened into individual attributes.
I apologise in advance if this is too vague or my ignorance is too salient - but I’d really appreciate some thoughts on this. Thank you.
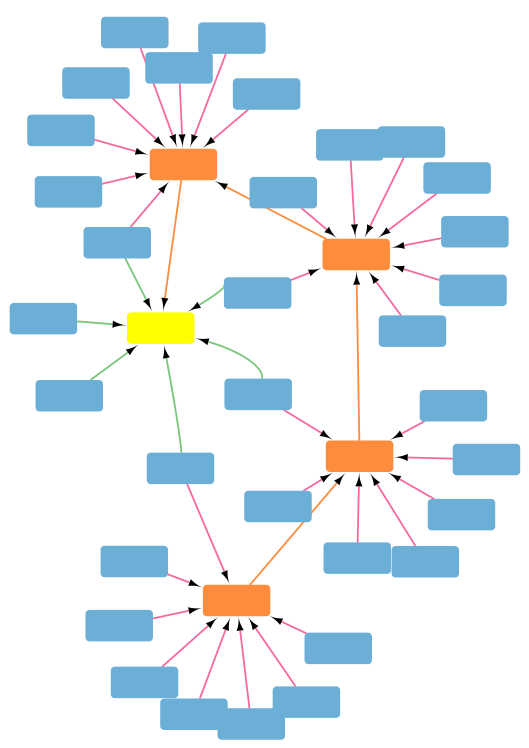
REFERENCE IMAGE: yellow node is the current prediction race (still of type Race but highlighted to aid visualisation), blue nodes are horses, orange nodes are races, orange edges are Precedes, green edges are Runs, pink edges are Run Outcomes. In this graph, only 4 horses have historical races (1 each.)