
Hello,
I am working on a project that classifies an edge on my graph.
In my homogenous multi-graph (simplified graph attached), I have nodes attributes of size of 3, and edge attributes of size of 2. For each edge, there is a binary label. My goal is to classify edge labels in the graph.
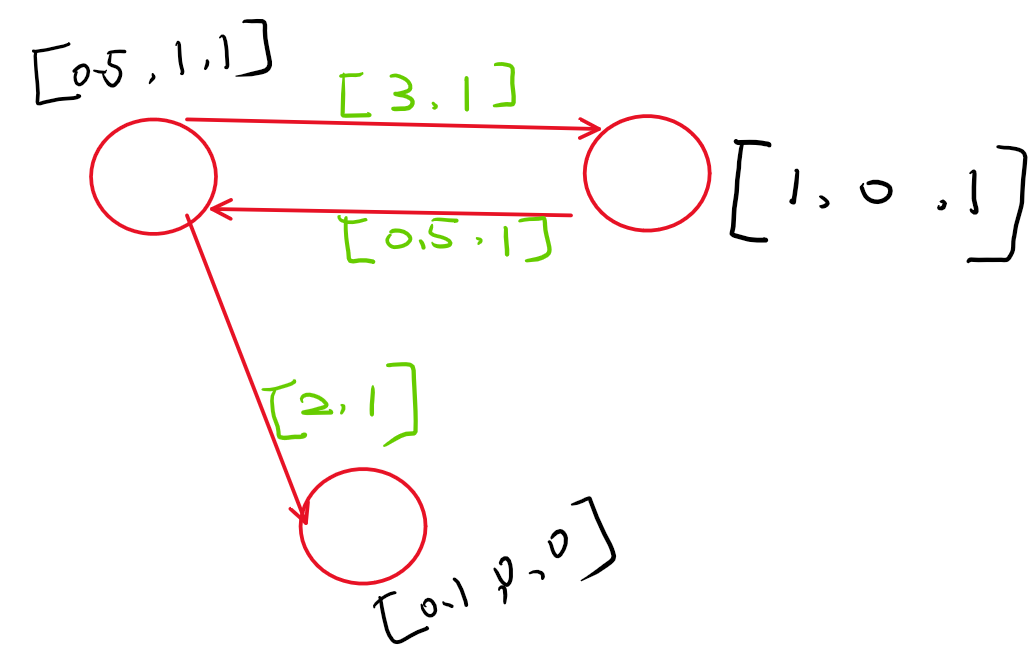
With above, I now have two questions.
1. what should be the appropriate way to organize the edge and node features together?
What I am doing now is I pad two zeros at the end of each node feature and pad three zeros at the beginning of the edge feature, so that each edge and node will have a feature vector of same size of 5.
Is it a proper way to organize features?
2. how should I propagate edge features?
What I am doing now is after update_all() nodes, in the apply_edge() I add the src and dst nodes to each edge:
edges.data[‘ef’] = edges.src[‘nf’] + edges.data[‘ef’] + edges.dst[‘nf’]
Same question here: Is it a proper way to propagate edge features?
Or you have any suggestions on propagating edge features.
Any suggestions would be appreciated.
Thanks.