
This post relates to Link Prediction on Sequential Graph Data - #5 by VladislavS, but I decided to make a separate post since that one’s over a year old. I too am also very new to this, btw.
Here’s my situation (extremely dumbed down to make this conversation easier):
Say I have a heterogeneous graph with these canonical edges:
person → is following → person
person–> is_protecting–> home
Some node attributes may include:
person: speed, position, heading
home: position
(notice they’re very kinematic)
Say I have a dataset of several of these graphs, where each graph represents a different time stamp throughout the day. I want to create a model that can train on these graphs, and do edge classification/link prediction to essentially predict the future state of the edges in the graph.
For example, given these four series’ of graphs:
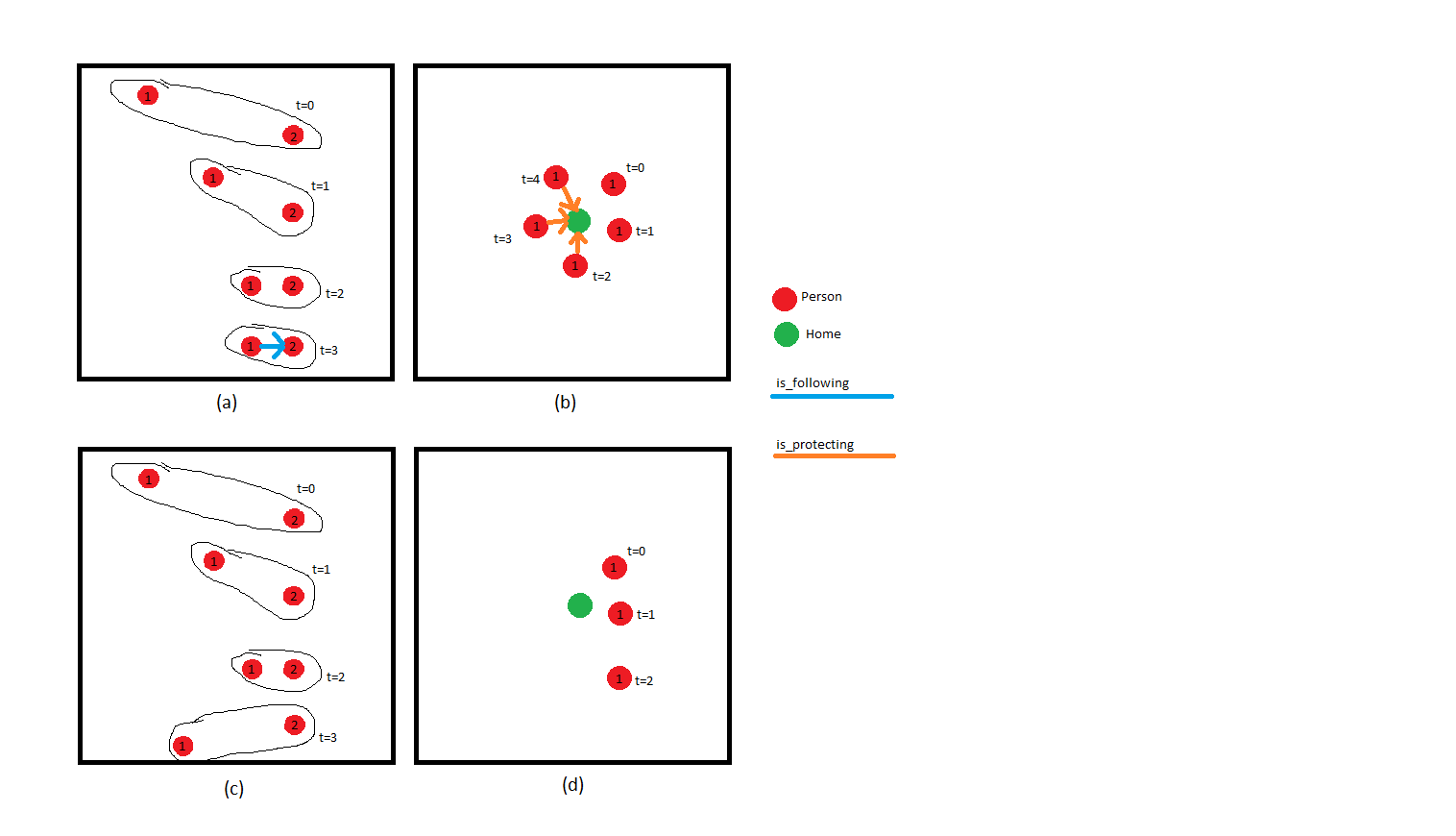
I want the model to predict the different edges in real time. For instance, in series (a), the graph starts off with two unrelated people. Using context from the whole series, the model should be able to predict that person 1 has begun following person 2 when their speed and headings start to match at t=3. In series (b), The graph model should only predict the protection link once the person has been close to the home for many consecutive timestamps. In other words, proximity alone isn’t enough to determine these links. It needs to be prolonged proximity
Series’ (c) and (d) show examples where links should not be predicted. Even though the proximity is there, it is not prolonged. The nodes are just passing each other.
And here’s the questions:
-
Is it better to represent the passage of time via one big graph of all the nodes at all the times, or a sequence of graphs each with all the nodes at one time? If it’s the former, a “moves_to” relation would be added to signify which nodes are the same. E.g. in series (a), between 1,t=0 and 1,t=1
-
Does something simple like GraphSAGE have the ability to factor in the temporal context for link prediction, or would I have to go the Generative Models of Graphs route?
-
Is PinSAGE a generative model? Aka is a recommender system a type of a generative model, and would that apply here?
-
If I go the “one big graph” route, the graphs can be very big (millions of nodes), so I’m looking at several approaches to accommodate this
- GraphSAGE trained using the heterogeneous graph convolution model stochastically
- GraphSAGE trained using the heterogeneous graph convolution model on multiple GPUs
- Generative Model trained on heterogeneous data stochastically
- Generative Model trained on heterogeneous data on multiple GPU’s
- Are models like GraphSAGE and generative models mutually exclusive?
I’m not sure if any of these are the way to go, much less even possible, but I’ve only been doing this for a few weeks. What do you guys think?