
Hello!
Starting from the current example of Pinsage using Movielens, I am trying to apply the model to a slightly different bi-partite setting.
Currently, I am trying to implement a modified version of negative sampling that involves sampling nodes which are close in the neighborhood (see the image for a visualization of what I mean by this).
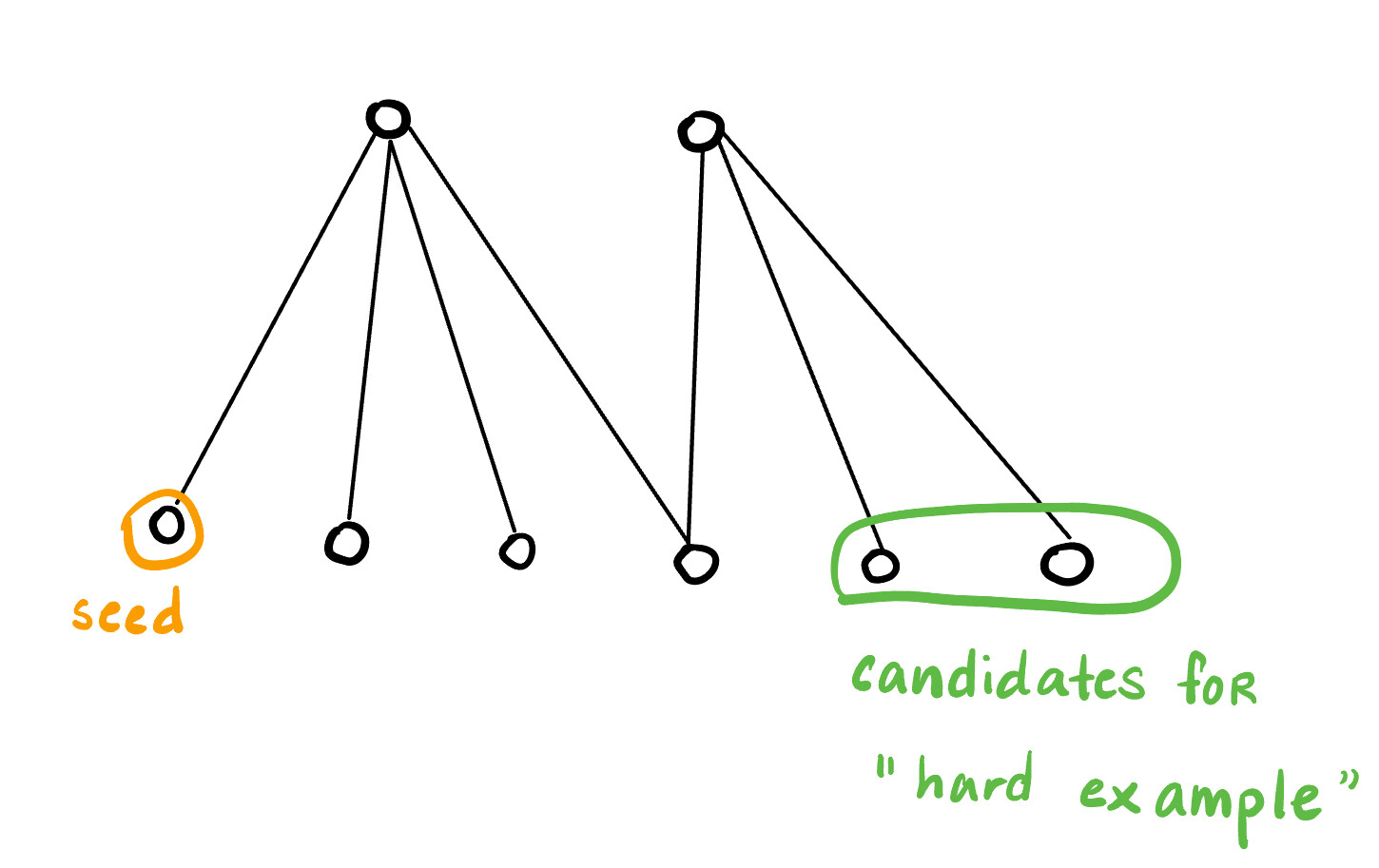
I tried to do this with the following code block:
@NODE_SAMPLER_REGISTRY.register('NEG_SAMPLE')
class SpecialItemToItemBatchSampler(IterableDataset):
def __init__(self, g, cfg):
self.g = g
self.user_type = cfg.DATASET.USER
self.item_type = cfg.DATASET.ITEM
self.user_to_item_etype = list(g.metagraph()[self.user_type][self.item_type])[0]
self.item_to_user_etype = list(g.metagraph()[self.item_type][self.user_type])[0]
self.batch_size = cfg.DATASET.SAMPLER.NODES_SAMPLER.BATCH_SIZE
def get_negs(self, heads):
neg_tails = []
khop, _ = dgl.khop_in_subgraph(self.g, {'track': heads}, k=4)
for seed in heads:
parent_playlist = self.g.predecessors(seed, etype='contains')
mask = self.g.has_edges_between(khop.ndata['_ID']['track'], parent_playlist, 'contained_by')
neg_options = khop.ndata['_ID']['track'][~mask]
neg = torch.tensor(np.random.choice(neg_options, 1))
neg_tails.append(neg)
return torch.cat(neg_tails)
def __iter__(self):
while True:
heads = torch.randint(0, self.g.number_of_nodes(self.item_type), (self.batch_size,))
tails = dgl.sampling.random_walk(
self.g,
heads,
metapath=[self.item_to_user_etype, self.user_to_item_etype])[0][:, 2]
neg_tails = self.get_negs(heads)
mask = (tails != -1)
yield heads[mask], tails[mask], neg_tails
and yet, when I try to run this, I am getting Runtime Error raise RuntimeError('DataLoader worker (pid(s) {}) exited unexpectedly'.format(pids_str)) from e and RuntimeError: DataLoader worker (pid 2938) is killed by signal: Segmentation fault.
I’ve tested on a small scale graph (see image below but ignore the labels on the nodes since they do not account for bi-partite ids):
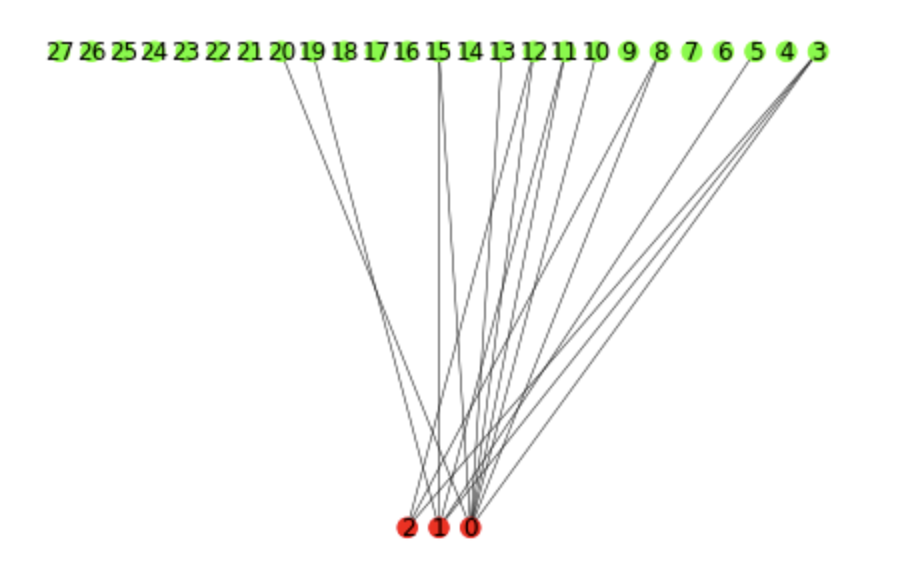
and I can confirm that
neg_tails = []
heads = torch.tensor([5,7,2,0])
khop, _ = dgl.khop_in_subgraph(g, {'track': seed}, k=4)
khop.remove_nodes(heads, 'track')
print(khop.ndata['_ID'])
for seed in heads:
parent_playlist = g.predecessors(seed, etype='contains')
mask = g.has_edges_between(khop.ndata['_ID']['track'], parent_playlist, 'contained_by')
neg_options = khop.ndata['_ID']['track'][~mask]
neg = torch.tensor(np.random.choice(neg_options, 1))
print("seed:{}, parent:{} neg:{}".format(seed, parent_playlist, neg))
neg_tails.append(neg)
torch.cat(neg_tails)
returns the following seemingly correct output:
{'playlist': tensor([0, 1, 2]), 'track': tensor([ 2, 7, 8, 10, 16, 17])}
seed:5, parent:tensor([0, 2]) neg:tensor([7])
seed:7, parent:tensor([0]) neg:tensor([2])
seed:2, parent:tensor([1]) neg:tensor([7])
seed:0, parent:tensor([0, 1, 2]) neg:tensor([2])
Can anyone advise on what I’m doing wrong?