Hi,
I am running into a strange problem where dgl (version 0.4) seems to fail when I push the graph to gpu. It works on a K80, or my local machine’s gpu. Has anyone seen this before?
Run on local machine: it works (GTX1660)
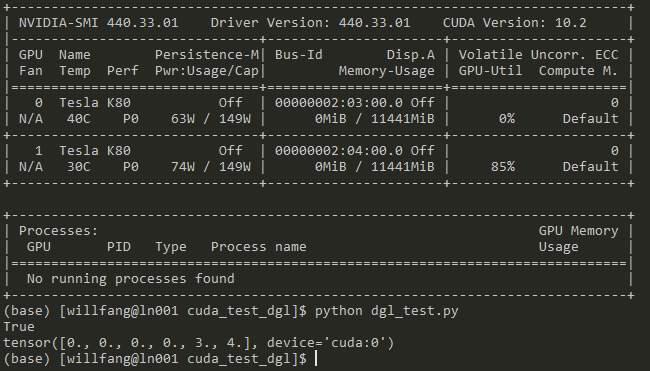
Run on cluster’s interactive window: it works (K80)
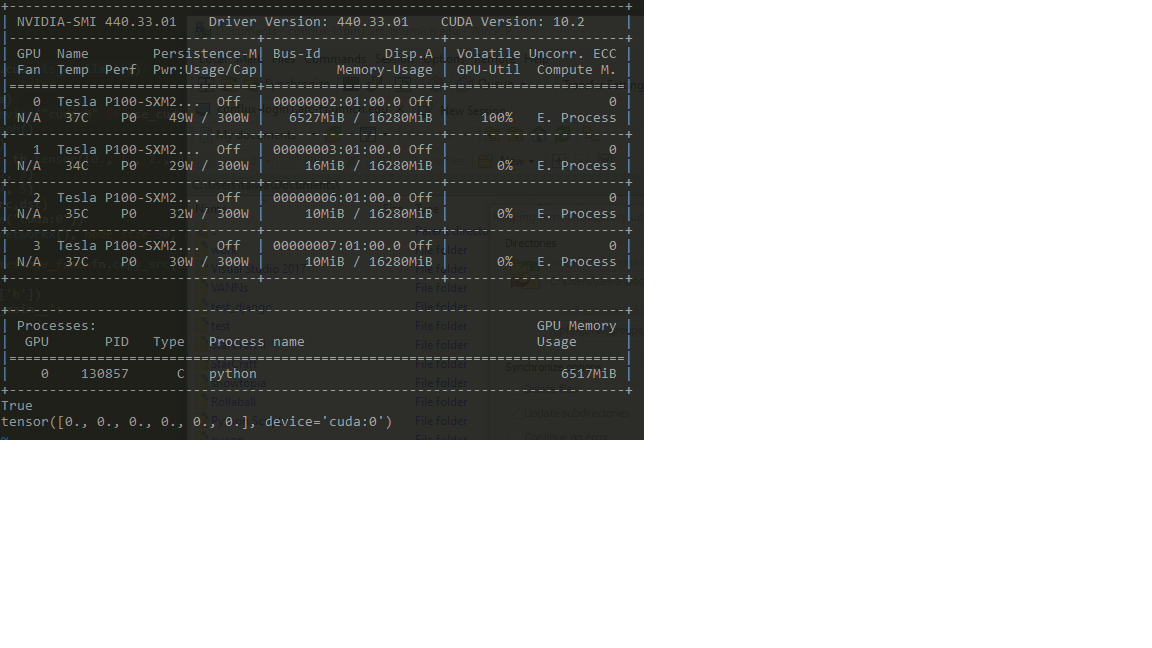
Submit job to cluster: fails (P100)
A difference I’ve noticed is the difference in GPU
import dgl
import networkx as nx
import matplotlib.pyplot as plt
import torch as th
import dgl.function as fn
def main():
use_cuda = th.cuda.is_available()
# use_cuda = False
print(use_cuda)
device = th.device("cuda:0" if use_cuda else "cpu")
g = dgl.DGLGraph()
g.add_nodes(6)
g.ndata['h'] = th.tensor([0., 1., 2., 3., 4., 5.]).cuda()
src = (1, 1, 2, 3)
dst = (4, 5, 4, 5)
g.add_edges(src,dst)
g.to(th.device("cuda:0"))
nx.draw(g.to_networkx(), node_size=50, node_color=[[.5, .5, .5,]])
# plt.show()
g.update_all(message_func=fn.copy_src(src='h', out='m'), reduce_func=fn.sum(msg='m',out='h'))
print(g.ndata['h'])
if __name__ == '__main__':
main()