
have any one faced this problem? training dgi use the model provided in dgl/emamples
I tried to run the commands in README: dgl/examples/pytorch/dgi at master · dmlc/dgl · GitHub and all works as expected. I built the DGL with latest master branch, ubuntu.
which DGL version/platform are you using? and what exact command are you using for running example?
I use the model provided in dgl/examples/torch and one model provided by pyG, the loss explodes after many epochs
is there any thing wrong with my graph construction?
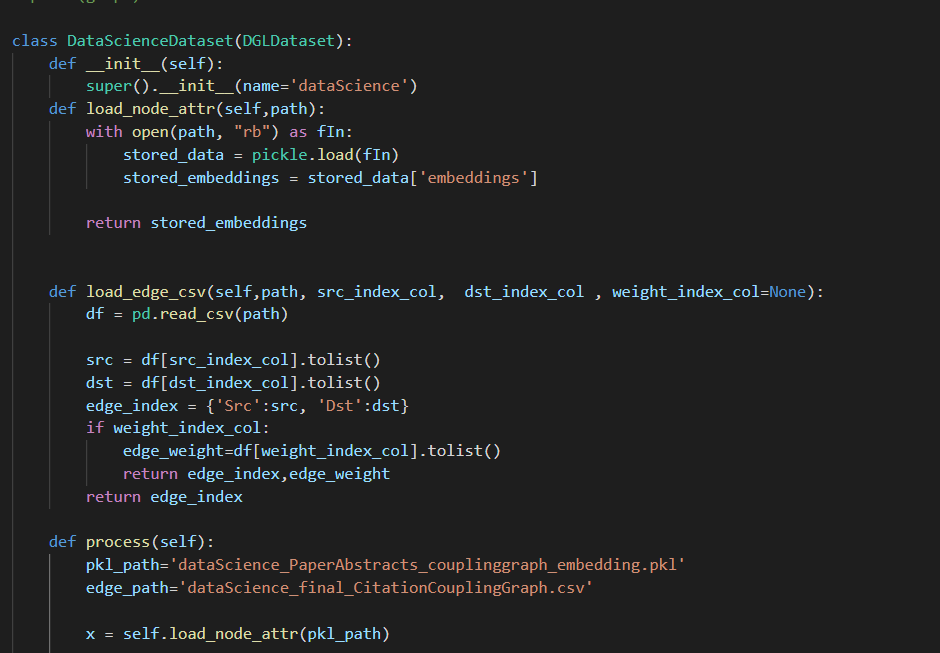
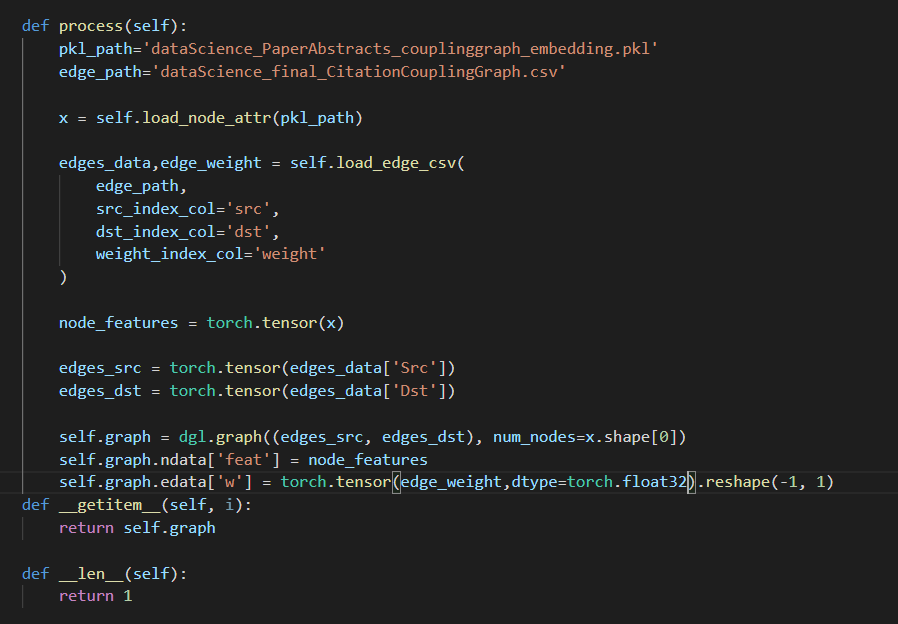
graph construction looks good to me.
as you used multiple models in your train, there may be something unexpected in you model train. have you tried early stopping, tune learning rate? why do you run so may epochs? validation loss is still decreasing?
I first used the code provided by the pyg official pytorch_geometric/infomax_inductive.py at master · pyg-team/pytorch_geometric · GitHub, and the loss explosion occurred in the first few epochs. After that, I used the dgi code provided by dgl, firstly I changed the original code to minibatch training, but the loss explosion still occurred. then I use the original model
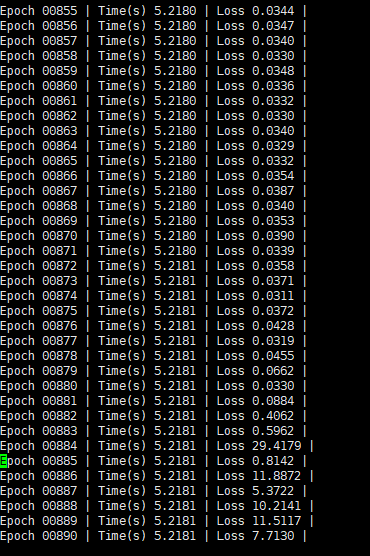
I implemented early stoping, in order to see if there will be loss explode, I set the number of epochs to be very large, set the patience value of earlystop to 100, at this 125730 node, 195448566 edge graph, the loss is still declining for so many rounds of training.
and this is the training loss, not the validation loss.
The key problem is that the loss will suddenly increase, and then it will reach the earlystop threshold.
hi @Rhett-Ying I have another question, if my node feature is randomly initialized, should I add the features to the optimizer? thanks.
You can set requires_grad to the tensor, such as node_features.requires_grad_()
and do optim = SGD(list(model.parameters())+[node_features]) to include it in the optimizer.
For the loss explosion problem, I would suggest try GAT and GraphSAGE model instead of GCN. Since there’s sampling included in the training process, GCN might not be stable in such cases
thank you for reply, yes, sampling might be the cause of loss explosion, so I train the network on the whole graph without minibatch, but loss explosion still occur after few hundreds epoches.
as for GAT, I dont know how to implement attention weights and predefined edge weight together, can you help me, thanks.
You don’t need predefined edge weight. It’s computed based on the node features
hi @VoVAllen , I want to learn paper embedding through a citation coulping graph, so I need to add coupling strength as edge weight.
If paper A cites paper [C,D,E] and paper B cites paper [D,E,F,G], then the coupling strength between AB is 2, I normalized the coupling strength by devide total references number of each paper.
hi there, another question: if I want to get node embedding after training, should I call the forward(g) to calculate the representation or use the node_features metrix directly?
Either way works. Common approaches uses node embeddings which is node_features. I’ve also seen people using the last GCN layer output as the embedding for downstream tasks.
You can add the strength you defined as part of the loss
Hi @VoVAllen , can you describe in detail how to add the strength into loss? I am currently using the deep graph infomax framework for unsupervised training。
How did you calculate this coupling strength? Can it be backpropagated?
no , I predefined when building the graph.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.