Hi, I want to modify the DGI example for inductive settings with PPI/Reddit datasets. Would appreciate any pointer on how to start.
Thanks!

Hi, I want to modify the DGI example for inductive settings with PPI/Reddit datasets. Would appreciate any pointer on how to start.
Thanks!
Hi! I think the major modification you would need is to implement a mini-batcher, so you can perform a subsample of the PPI/Reddit datasets so they can fit in memory (using mini-batches).
Perhaps the PPI dataset can fit in memory if you separate batches of complete graphs (such as implemented here), however the Reddit is composed of a single graph, which could be split using DGL’s NeighborSampler (as shown here). Even so, I understand that NeighborSampler has some limitations that DGL’s mainteners are planning to overcome by implementing a new feature. Maybe they can comment more on that.
BTW, if you plan to follow the paper’s implementation, you will of course need to change the neural network architecture accordingly (the transductive cases were solved using a one-layer GCN model).
In addition to the great suggestions by @Lgcsimoes, you may find our example of GAT on PPI to be helpful: https://github.com/dmlc/dgl/blob/master/examples/pytorch/gat/train_ppi.py
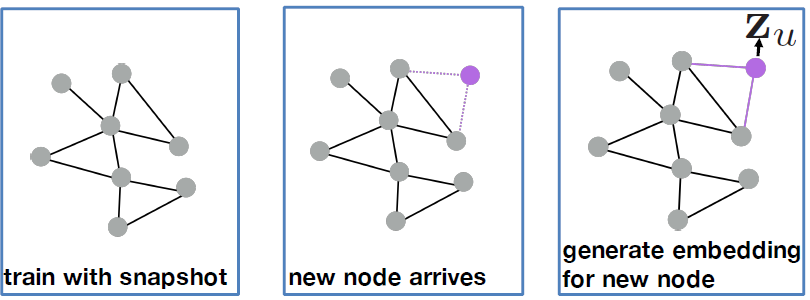
Thanks a lot for the recommendations. Since I want to generate embeddings for new nodes attaching the original graph during inference, not necessary a completely new separate graph like PPI, I think I’m leaning toward the Reddit dataset more.
The NeighborSampler is interesting. Is it able to generate overlapping subgraphs for train/test? For my problem, at test time, I have a small test graph consisting of old + new nodes to modify or generate new embeddings. Edges between old nodes might already be seen in training, but edges between new nodes or old-new nodes are unseen.
On a separate note, if I have a N-ary tree dataset similar to Tree-LSTM tutorial (except nodes can belong to multiple trees), can I pick my seed_nodes = root and num_hops = tree-depth, to batch-train my DGI, with each batch being a single tree?

Thanks again!
NeighborSampler to separately sample from them during training and test.For 1., could you elaborate a bit more on that? Originally I was thinking of setting up overlapping train_nid and test_nid (since a node can appear in both) and use those as seed_nodes in NeighborSampler.
With NeighborSampler, you cannot avoid sampling particular edges from a graph (e.g. the edges between old-new nodes). Therefore I recommend you construct one graph for training and one for test. The training graph consists of old nodes only.