Hi,
in some of the example code in the doc I see this method to go to a higher feature dimension/more features per node:
self.conv1 = dglnn.GraphConv(in_dim, hidden_dim)
self.conv2 = dglnn.GraphConv(hidden_dim, hidden_dim)
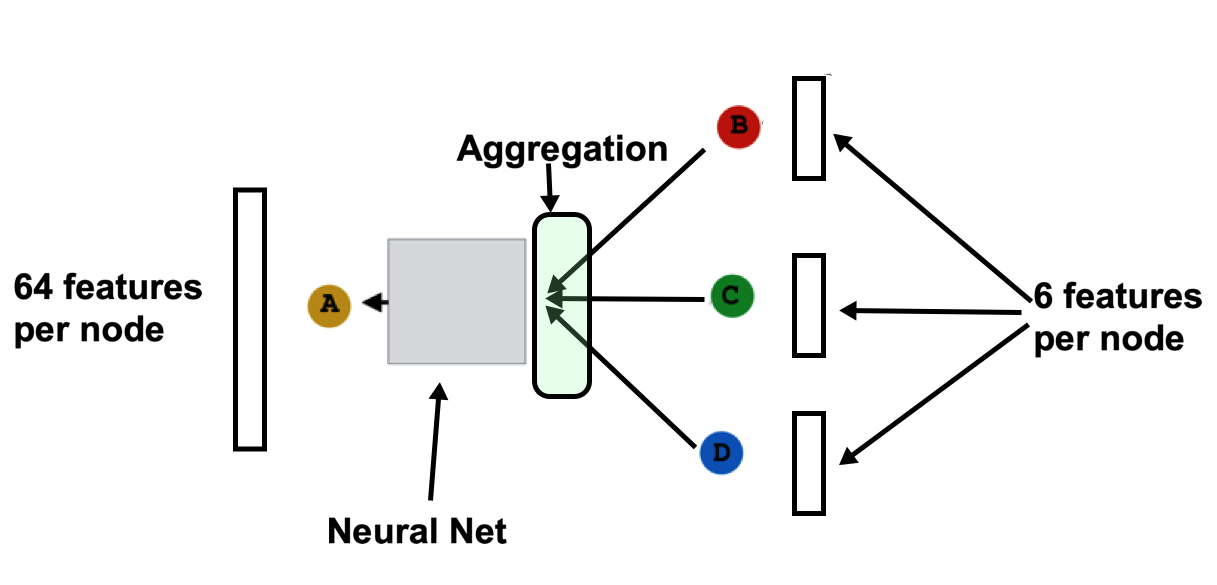
Here the first graph convolution layer is used to go to a higher feature dimension. However, if my in_dim is 6 and I want to go to for instance a hidden_dim of 64, does this then actually work well? As I understand it now, the aggregation function in GCN’s is often something like sum or average and if I then sum/avg the 6 features of neighbouring nodes and only then apply the neural net part of GCN to go to 64 features, a lot of the information that was encoded in my neighbouring nodes is lost by the sum/avg operation before any learning is applied, right?
Wouldn’t it then be better to, in some way, blow-up the 6 features to 64 features per node and only then apply the GCN?
Kind regards,
Erik