
Similar to this this question. I’d like to implement relational attention proposed in this paper
Hi, I’d like to implement the function as follows:
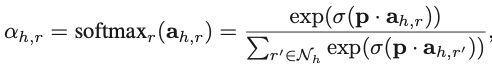
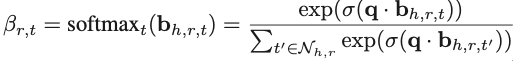
That is, I need to calculate the attention alpha between the head entity and relations, and need to calculate the attention belta between relation and tail entity.
So, How can I use dgl to implement attention score in terms of a part of neighbors, not all neighbors?
Note: I can implement it in the numerator, but it’s not clear how do I compute the denominator
![]()
![]()
The above is the explanation of the Dimension of the tensor in the softmax function where num_edge is the number of all edge_index.
I find it difficult to compute alpha and beta at the same time. If I filter index via edge_type, that is I focus on the subgraph about relation_i. Then beta attention could be implemented while alpha is still hard to address.
For example, if I mask edge_type i, then in the self.propagate, the edge_index is all about r_i. So as for attention alpha, I couldn’t know the other relations which are the neighbors about entity u.
The desired final result shows below:
For example:
attention_{e_1,e_2} = alpha_{e_1,r_1} * beta_{r_1,e_2}
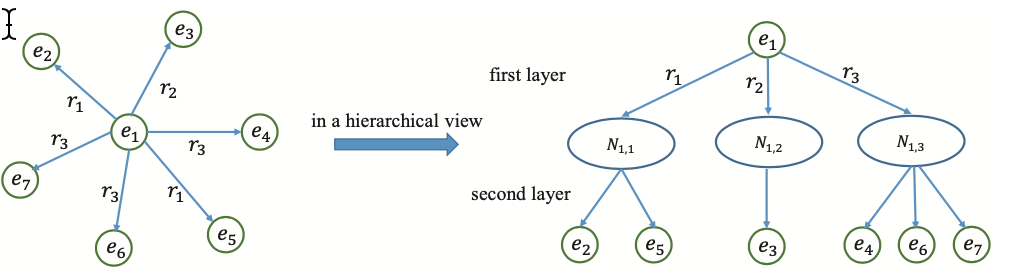
Looking forward to your help! Thanks a lot!