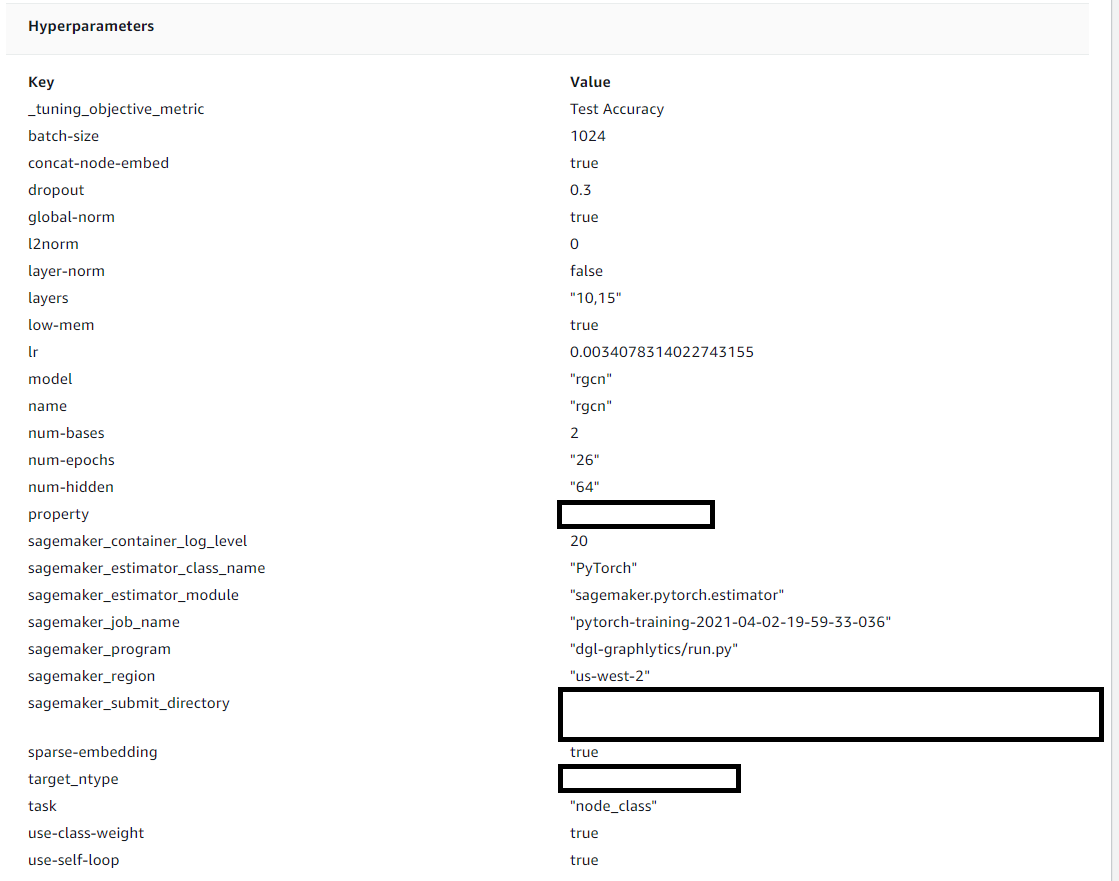
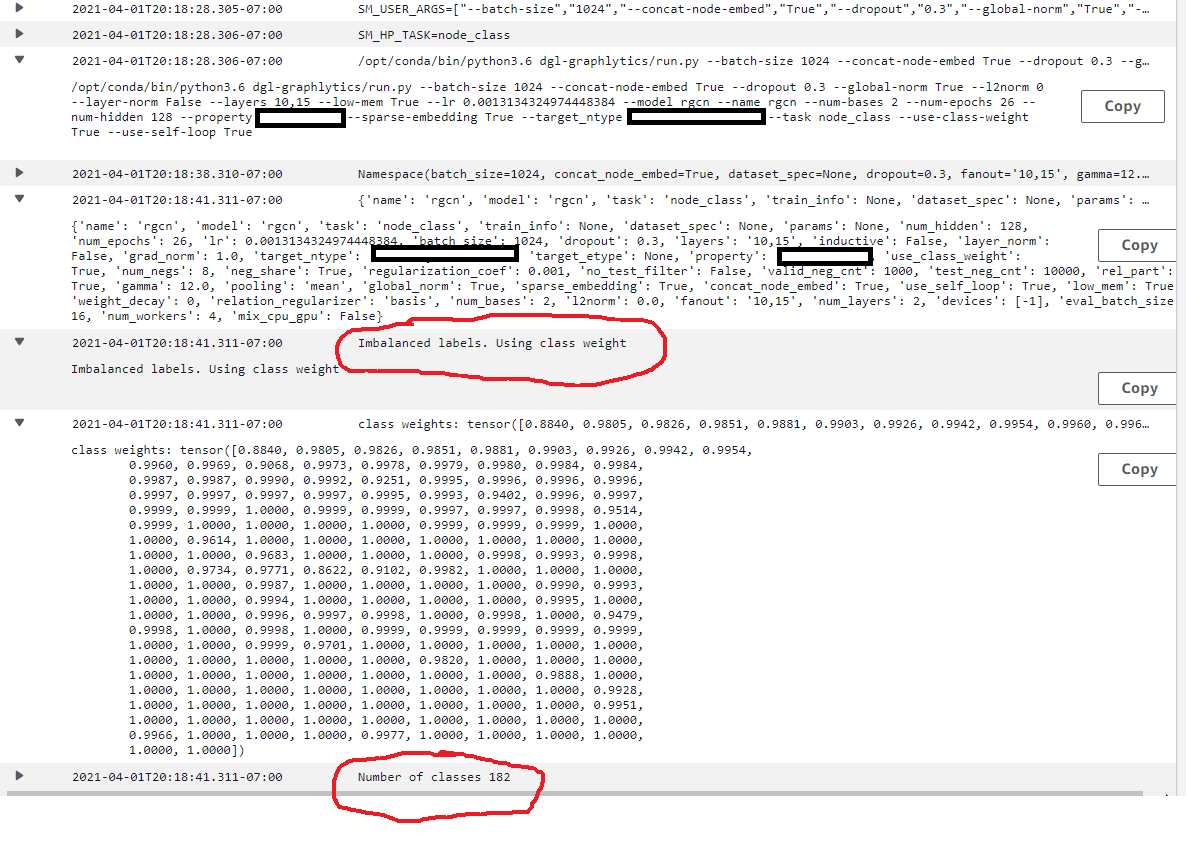
I’ve got a graph that has 18 edges, and 15 nodes. I’m training it with Sagemaker, using a ml.m5.2xlarge instance. It’s taking over an hour. I’m getting close to 100% “Training Accuracy” within 10 or so epochs. The training objective I’m using is “Test Accuracy”, which is low, like 0.16.
Train Accuracy: 0.9850 | Train Loss: 0.0430
Epoch 00012:00026 | Train Forward Time(s) 0.0162 | Backward Time(s) 0.1528
Validation Accuracy: 0.1603 | Validation loss: 9.4638
What kinds of things should I be doing to address this? Seems like its overfitting the data. I’m using a HPO job on Sagemaker, so any specific guidance with that would be great. Thanks.