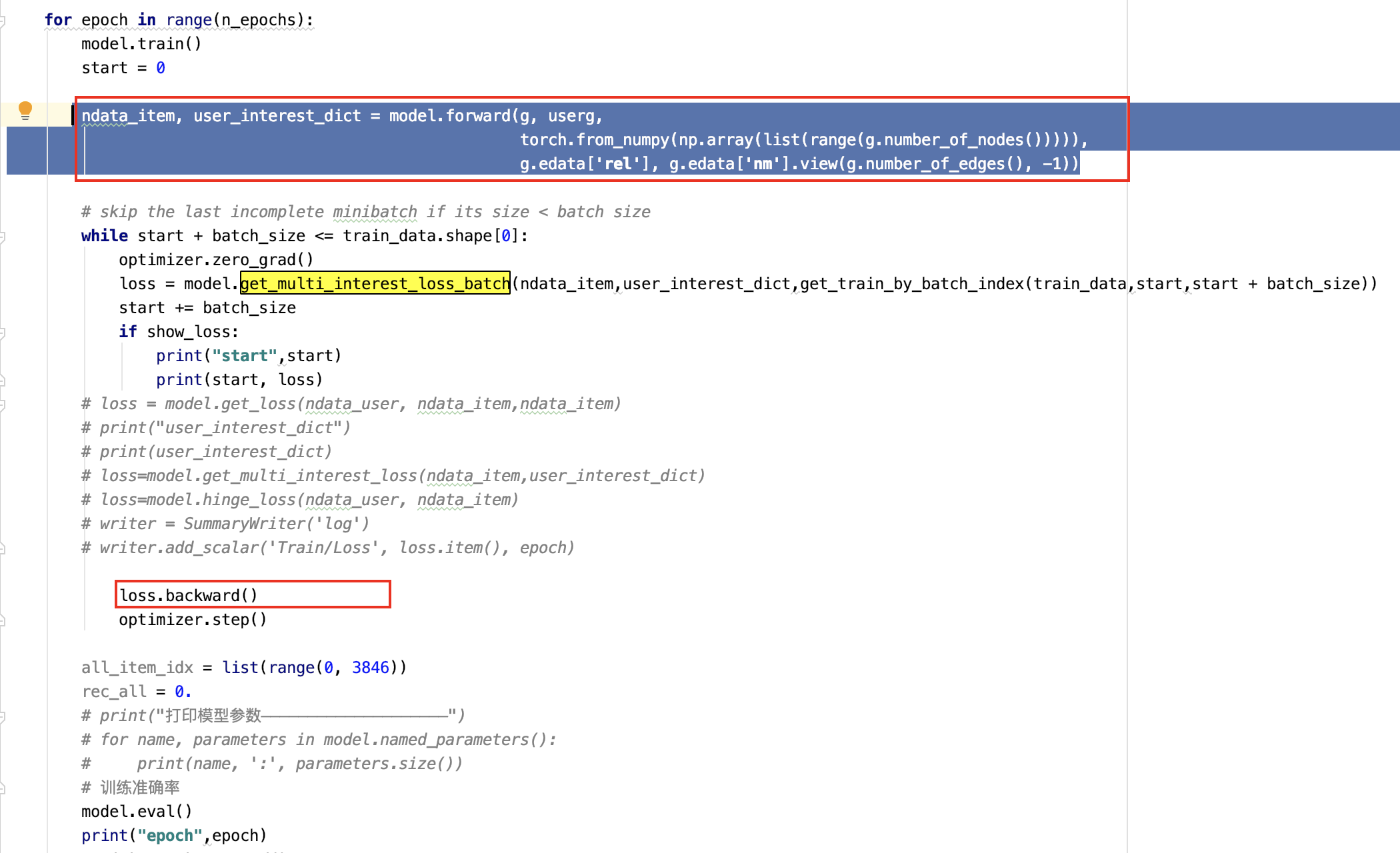
How to do only one forward propagation per epoch and multiple back propagations?
I want to get the vector representation through several layers of graph neural networks first,
then do the backward operation to optimize the loss according to the batch number.
what i want to do is in code B.
the main difference is the position of ’ user_embedding, item_embedding = model(G)’
but an error will occur in code B
: TypeError: cannot unpack non-iterable NoneType object
is there any way to do this?
the same error:link
thank you!
#code A
model = Model(G, 8, 8, 8)
opt = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
for epoch in range(2):
for batch_data in dataset:
optimizer.zero_grad()
user_embedding, item_embedding = model(G,user_embedding, item_embedding)
loss=model.getloss(batch_data)
loss.backward()
optimizer.step()-----------
#code B
model = Model(G, 8, 8, 8)
opt = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
user_embedding, item_embedding = model(G,user_embedding, item_embedding)
for epoch in range(2):
for batch_data in dataset:
optimizer.zero_grad()
loss=model.getloss(batch_data)
loss.backward()
optimizer.step()