
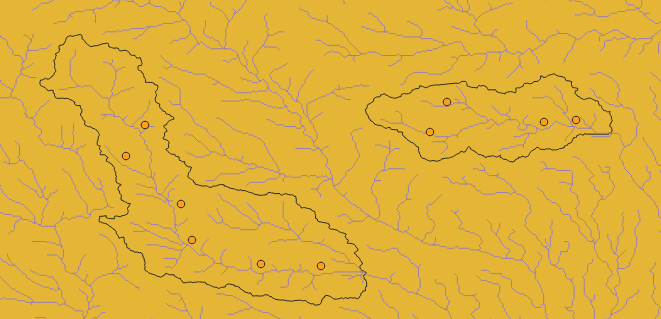
The two polygons which have black outlines are hydrological basins,and purple lines represent rivers,yellow points represent hydrological stations.
It’s obvious that points and rivers in a basin can be organized as an directed graph(direction is decided by river flow direction),so hundreds of basins can be seen as hundreds of graphs,and different basins have different hydrological laws to predict streamflow of rivers.
However,all basins(or all graphs) are all homogeneous,so should I use a big graph with hundreds of splitting assemblies,or plenty of small graphs and use GraphDGLDataset to load them?
Hope for your reply,thanks.
You need to prepare your data, then you can use the CSVDataset to load the data.
Refer to Loading data from CSV files.
It’s hard to give you a concrete example without know your data.
Every stations is pandas Dataframe with only three columns:precipitation, level and streamflow.
It looks like that:
time basin precipitation level streamflow
2024-1-1 00001 1.0 2.0 1.5
2024-1-2 00002 1.1 2.5 2.1
……
That depends on what task you wish to achieve. Do you wish to train a separate model for each basin (in which case DataLoader doesn’t matter; it’s best to have a script that takes in a single basin as input), or do you want to train a shared model for all the basins (in which case you could use GraphDGLDataset)?
A shared model for all the basins.