
Hi ! I’m quite curious about the baselines of heterogeneous GNN. Now I want to start with learning state-of-the-art baselines ,so my question is, which baselines should I focus on? (I’ve known that RGCN seems to be a baseline , now I want to know more)
There are many heterogeneous GNNs in this repo: GitHub - BUPT-GAMMA/OpenHGNN: This is an open-source toolkit for Heterogeneous Graph Neural Network(OpenHGNN) based on DGL.
Have fun!
Hey @mufeili , DGL team might want to take a look at the paper below. It is already implemented using DGL. Apparently it shows that greater performance can be achieved without having to deal with the inefficiencies of heterographs: https://arxiv.org/pdf/2112.14936.pdf
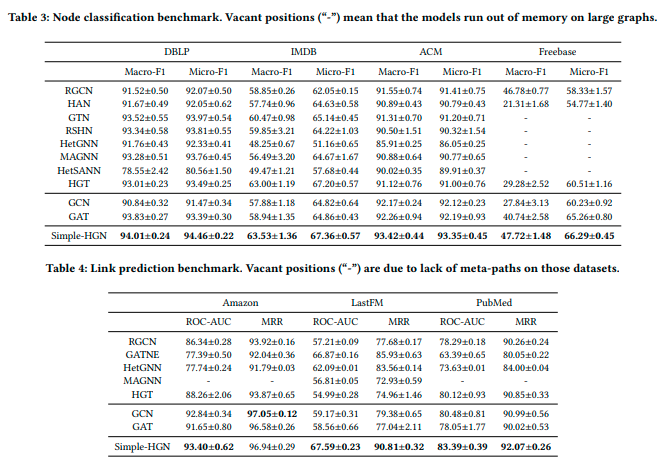
1 Like
Hi @felipemello , thank you for sharing this paper. We are aware of it and will further evaluate it.
1 Like
Hi @felipemello ,
Yes! It’s an interesting paper and has caused quite a discussion among us too. My hunch is that the dataset and task setup play a major role here. It is likely that those target node categories (e.g., book genre, paper topic) do not need to capture the distribution of its surrounding relations. This indeed shows the challenge in designing the right benchmark for graph machine learning.
@minjie @mufeili , I read it a while ago, so I dont specifically recall the details. But I think that their proposed network makes sense. You can read my interpretation below, but I am not specialist and might be misunderstanding it.
In HGT, for example, each node has its own layers, and then doing the message pass, there is a projection from node type A to node type B. In other words, each nodetype has its own distribution.
In homogeneous models there is no distinction between node types, so my understanding is that the model ends up embedding the node type on the embeddings itself. However, what these models lack is the second part of HGT: A specific projections from node type A to node type B.
This paper, as far as I recall, proposed to solve this projection part by adding a vector to node type A before adding it to node type B. My interpretation is that this is a more complex version of the classical word embedding example: QUEEN = KING - MEN + WOMAN, but in this case, node B = node A - TYPEA + TYPEB, and then a projection to fine tune things.
The expressive power might be smaller, but I would assume that it has greater regularization.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.