Hi @VoVAllen, I am sorry I didnt answer before. I missed the notification.
Sure! Are you familiar with attention mechanisms of transformers? Attention has a quadratic time/memory, because it compares every node with every node.
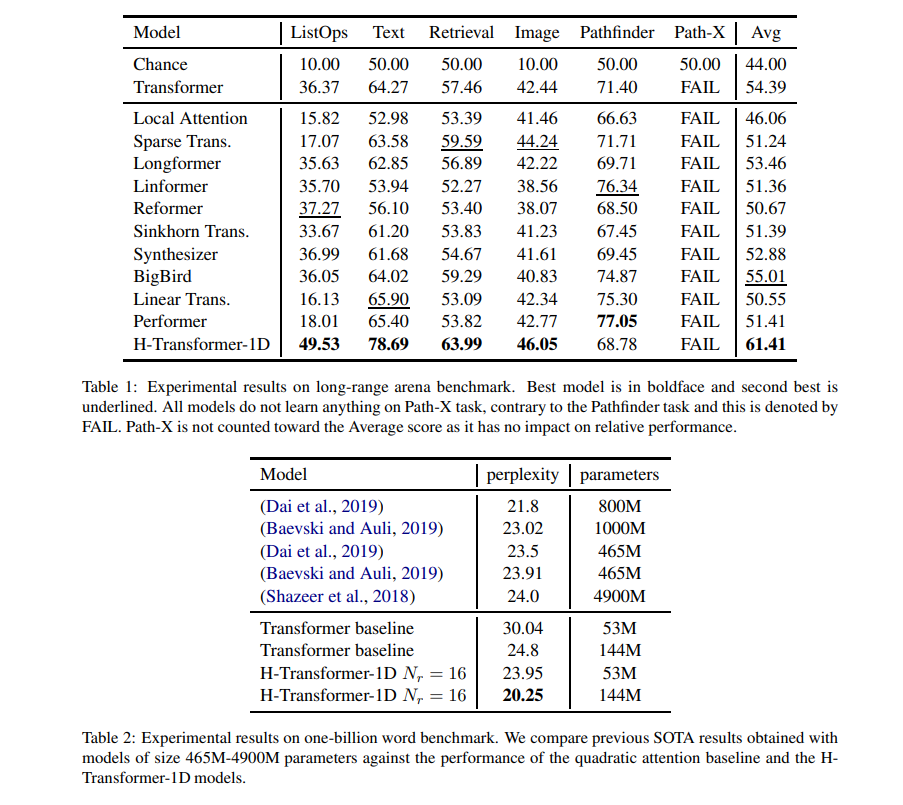
Linear attention tries to replicate the same mechanism, but with linear time/memory. This paper is relatively old, but it compares many transformers with different kinds of attentions. If you want to see their implementations, you can find most in lucidrains git.
You can find an interesting discussion here