
Hi, I followed tutorial stochastic training of GNN for link prediction to get the embedding of my graph, but it turns out that the embedding of my nodes are all the same. I am wondering if something going wrong here.
Hi,
Please add more informations, such as your code, your model, and information about your graph. It’s hard to tell with the limited information in the picture.
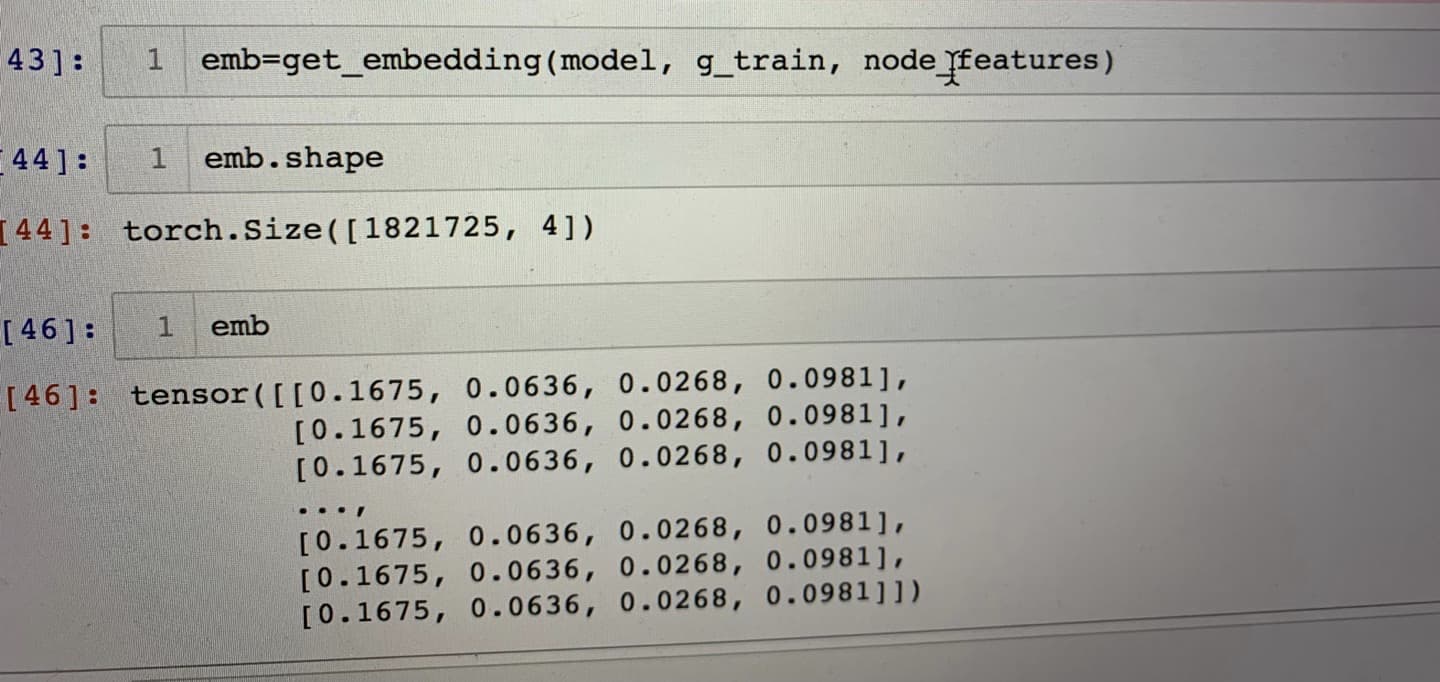
Ok. Basically my graph contains 932139 nodes and 1398984 edges. Since my graph has no node attributes at the moment, I simply initialize all nodes with a [1,1,1,1] tensor. My model and training loop are the same as the tutorial’s Stochastic Training of GNN for Link Prediction — DGL 0.7.1 documentation.
Don’t initialize with the same feature. Use random initial feature, or learnable embedding table instead. Same feature for all node easily results into same features after the forward process
Or one hot degree as feature, if the largest degrees is not so big
Ok, I will try to use random initial feature first. Among the options you offer, which one you think would be optimal to do?
And do you think I should increase the dimension of node feature? I am afraid 4-dimension is not enough to represent all nodes.
Dimension is not the key factor, and 4 is probably enough as the initial dim. You can try use Linear layer to extend it, which might have better results. Just try not initialize all nodes with the same features.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.