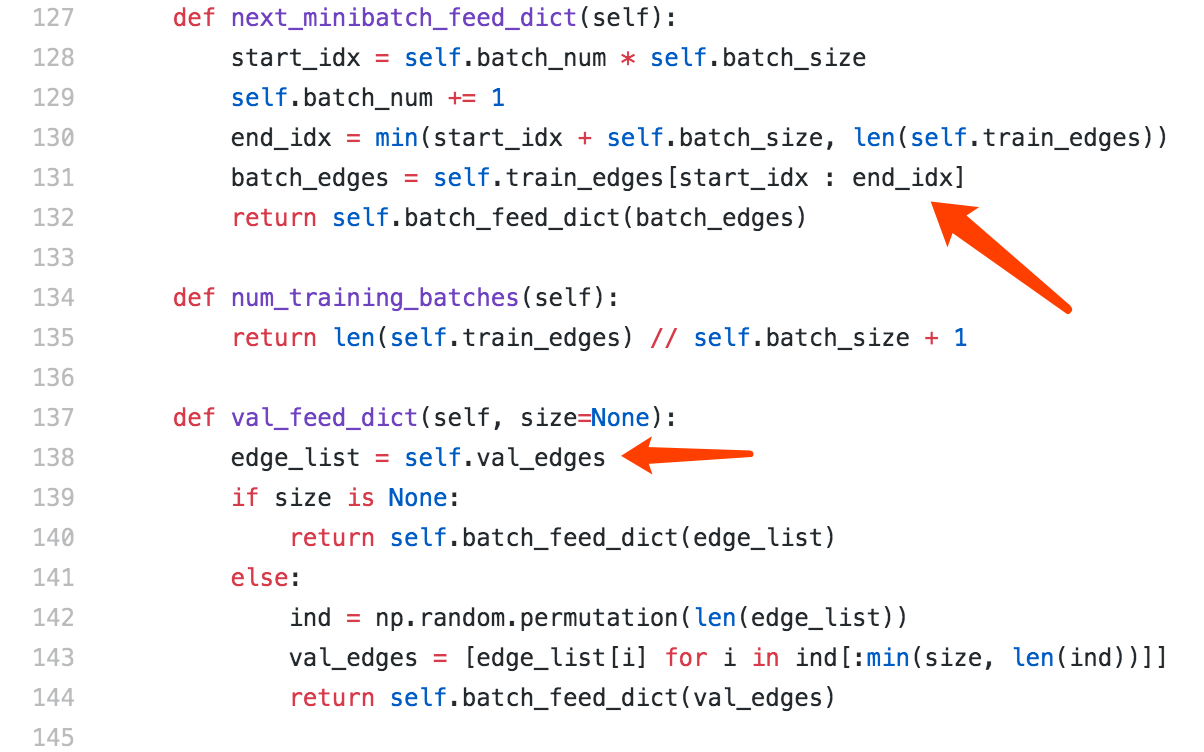
After read code from https://github.com/williamleif/GraphSAGE and DGL.
Based on my understanding, it seems that train nodes are [1,2,3,4,5] and valid nodes are [6,7]. We are training on [1,2,3,4,5], then how does [6,7] get the embedding for downstream model?
Thank you very much!