
I have a task of classifying spatial data from a geographic information system. More precisely, I need a way to filter out unnecessary line segments from the CAD system before loading into the GIS (see the attached picture, colors for illustrative purposes only).
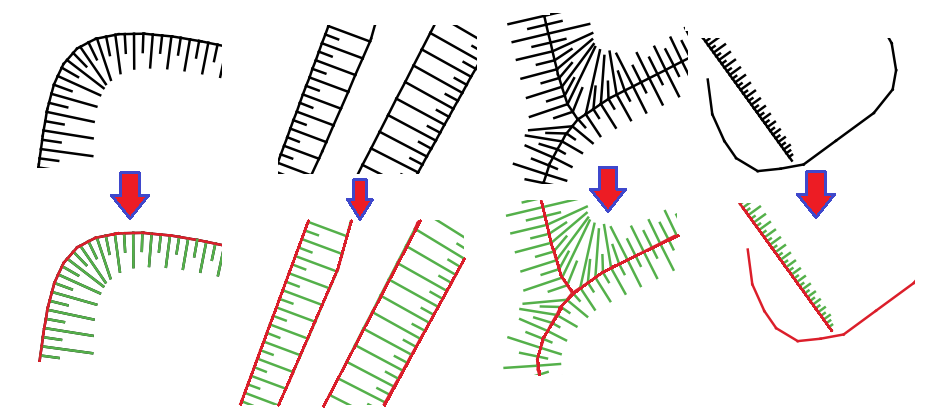
The problem is that there are much more variations of objects than in the picture. The task is difficult to solve in an algorithmic way.
I tried to apply a bunch of classification algorithms from the Scikit-learn package and, in general, got significant results. GradientBoostingClassifier and ExtraTreeClassifier achive an accuracy about 96-98%, but:
- this accuracy is achieved in the context of individual segments into which I explode the source objects (hundreds of thousands of objects) After reverse aggregation of objects it may turn out that one of their segments in each object is classified incorrectly. The error in the context of the source objects is high
- significant computational resources and time are required for the preparation of the source data, and calculation of features for classifiers
- it is impossible to use the source 2d coordinates of objects in algorithms, but only their derivatives
I tried to find good examples of using deep neural networks for this kind of tasks / for spatial data, but it seems that this direction is just starting to develop.
From what I learned, I realized that it would be a good idea to transform my spatial data into a graph and use graph neural networks to classify edge types (significant line / unnecessary line).
I converted data to a graph. As features of the nodes, I assigned the values of X and Y of the vertices of the geometry, and assigned to the edges the values of the length of the edge and its azimuth.
However, it turned out that if classification algorithms for edges exist, it is extremely difficult to find their implementation (I did not succeed). All the graph neural networks that I found are focused on the classification of nodes, whole graph and the prediction of the presence of edges, but not their classification.
Converting a graph into an line graph with the subsequent classification of nodes seems to be a possible solution, but it seems that when converting to an edge graph, the features of nodes and edges that are important for classification are lost (line_graph() function from the networkX python package).
I would like to get some guidance on solving my problem using DGL. Which algorithms I need to pay attention to, what examples to look at, or maybe there are simpler ways to solve my problem.
Also, please note that in general, I am new to deep learning and a simpler explanation may be required.