
import dgl
import torch
u, v = torch.tensor([0, 0, 0, 1]), torch.tensor([1, 2, 3, 3])
graph = dgl.graph((u, v))
sampler = dgl.dataloading.NeighborSampler([-1, -1])
dataloader = dgl.dataloading.DataLoader(
graph, [3], sampler,
batch_size=1,
shuffle=False,
drop_last=False)
for input_nodes, output_nodes, blocks in dataloader:
print(blocks)
print(blocks[0].edges(), blocks[1].edges())
I have the aforementioned script which creates a DGL graph (as shown here) as shown in the Fig
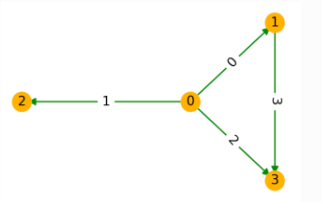 .
.
I assume the training node as node ID 3 and try to build a computation graph for a 2-layered GNN. The computation graph should have 1 node at Level 0 (node 3), 2 nodes at Level 1 (nodes 0 and 1) and
1 node at Level 2 (node 0). I print the MFGs generated using the aforementioned script. The output is -
[Block(num_src_nodes=3, num_dst_nodes=3, num_edges=3), Block(num_src_nodes=3, num_dst_nodes=1, num_edges=2)]
(tensor([1, 2, 2]), tensor([0, 0, 1])) (tensor([1, 2]), tensor([0, 0]))
I have the following questions -
- Is my understanding of the computation graph correct?
- If so, the MFGs generated do not match the computation graph at all.
- The second MFG has 1 dst node and 3 src nodes, but only 2 edges. How is that possible?