
I created the below heterogeneous graph and used the DataLoader to get mini-batches. But, the resultant graph contains the edge which is not in the original graph. Can you help me identify what causing this?
Graph:
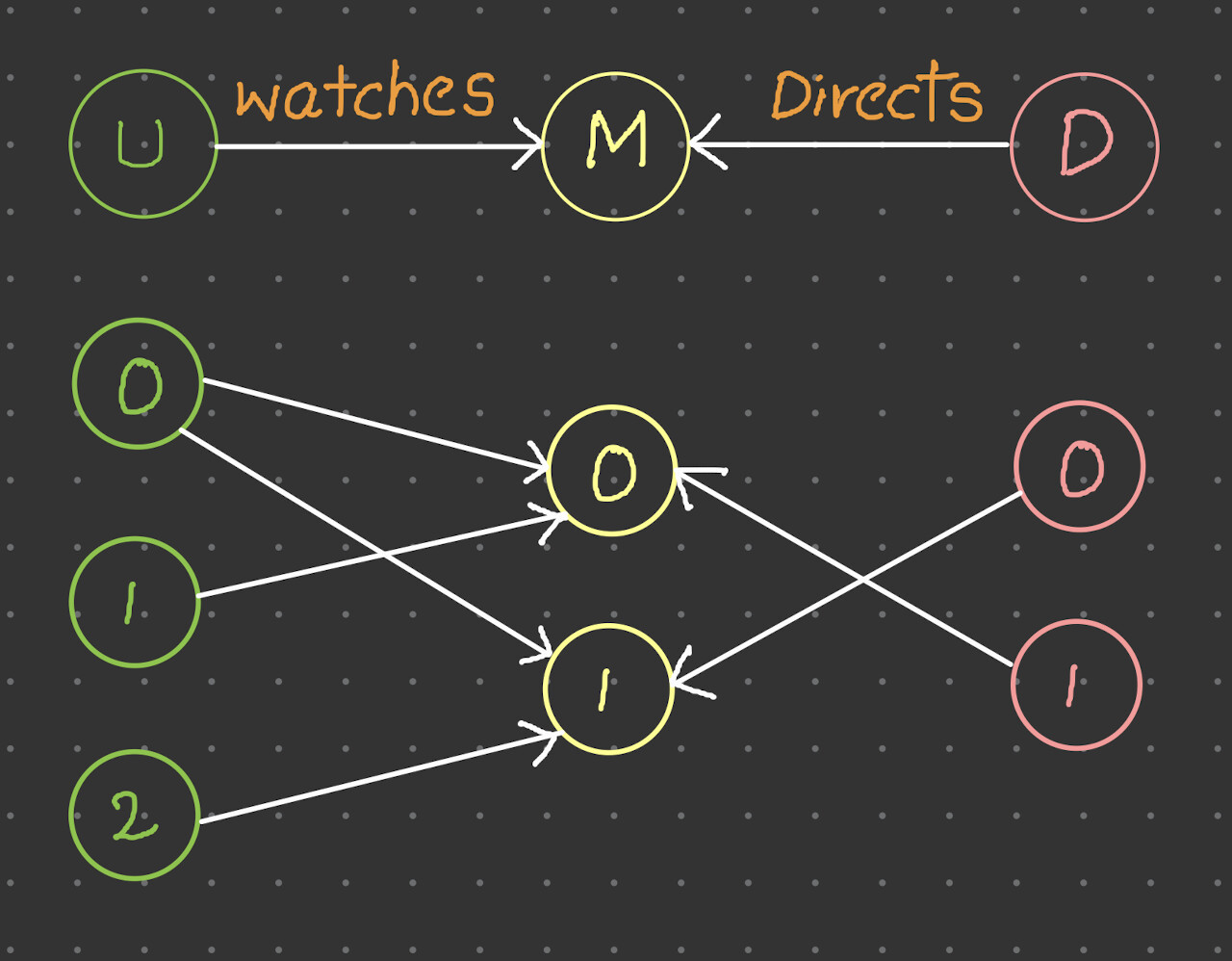
Code: Use the below code to reproduce the issue
import dgl
import torch
data_dict = {
('user', 'watches', 'movie'): (torch.tensor([0, 0, 1, 2]), torch.tensor([0, 1, 0, 1])),
('director', 'directs', 'movie'): (torch.tensor([0, 1]), torch.tensor([1, 0]))
}
graph = dgl.heterograph(data_dict)
train_eids = {
('director', 'directs', 'movie'): torch.tensor([0, 1]),
('user', 'watches', 'movie'): torch.tensor([0, 1, 2, 3])
}
sampler = dgl.dataloading.as_edge_prediction_sampler(
dgl.dataloading.NeighborSampler([5, 5])
)
dataloader = dgl.dataloading.DataLoader(
graph,
train_eids,
sampler,
batch_size=2,
)
input_nodes, pos_pair_graph, blocks = next(iter(dataloader))
for etype in pos_pair_graph.etypes:
print(etype, pos_pair_graph.edges(etype=etype))
# directs (tensor([0, 1]), tensor([0, 1]))
# - director_0 is never connected to movie_0 in the original graph, similarly, director_1 is never connected to movie_1 in the original graph (It should be vice-versa)
# watches (tensor([], dtype=torch.int64), tensor([], dtype=torch.int64))