
Hello!
I was reading through HGTConv implementation (the latest version) - and I can’t seem to find the non-linear activation. In the documentation it’s written as
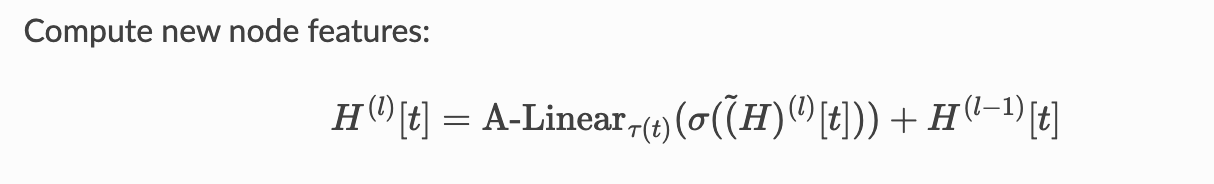
Where we sum residual connection and activation of the layer (which matches the paper schema https://arxiv.org/pdf/2003.01332).
However in the code we have:
h = g.dstdata["h"].view(-1, self.num_heads * self.head_size)
# target-specific aggregation
h = self.drop(self.linear_a(h, dstntype, presorted))
alpha = torch.sigmoid(self.skip[dstntype]).unsqueeze(-1)
if x_dst.shape != h.shape:
h = h * alpha + (x_dst @ self.residual_w) * (1 - alpha)
else:
h = h * alpha + x_dst * (1 - alpha)
if self.use_norm:
h = self.norm(h)
return h
It looks to me like no activation is done here at all. Can be bypassed by putting activation layer after HGTConv layer explicitly, but that doesn’t match the original paper.
Was this design intended?
Thank you!