
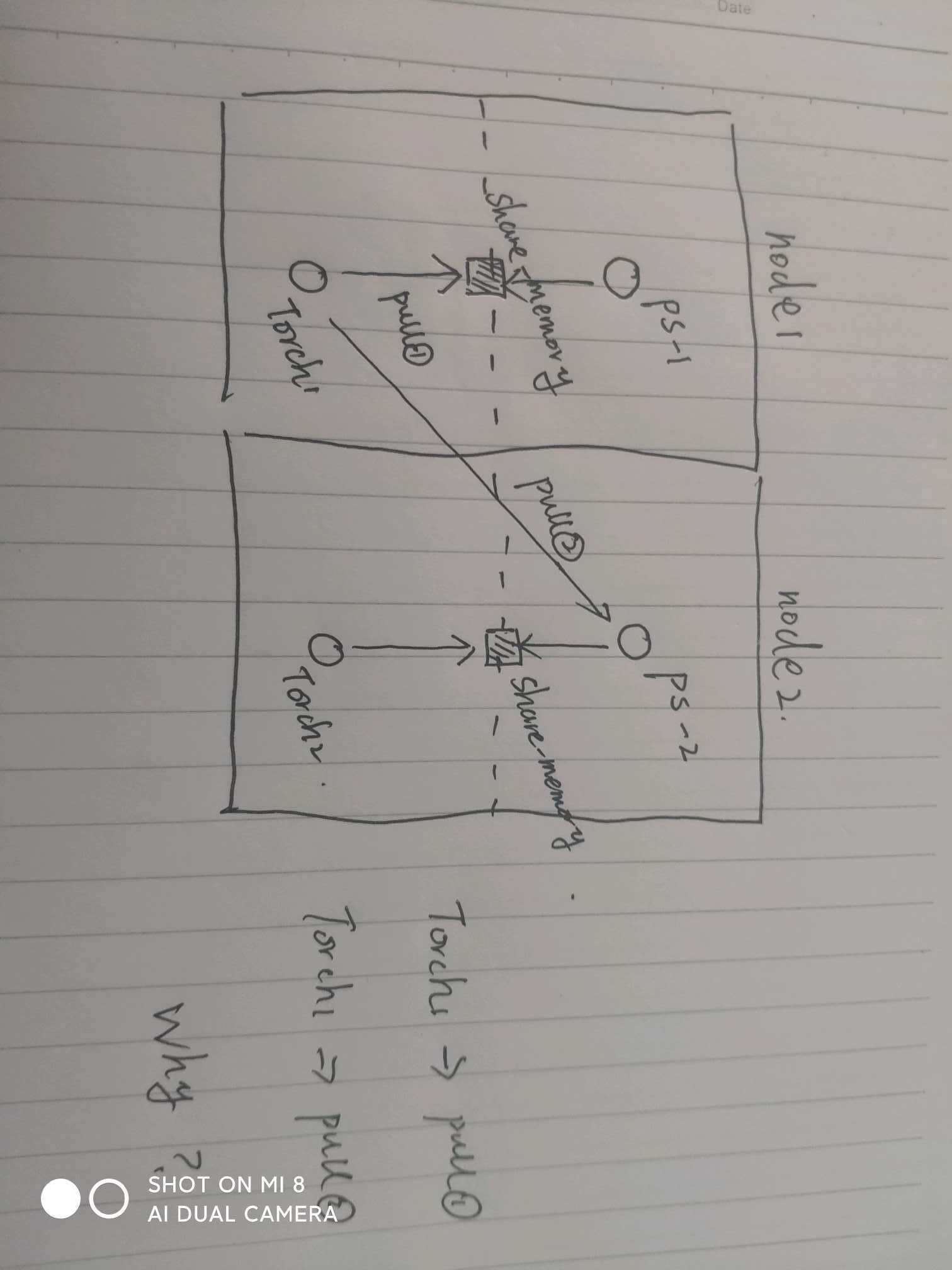
dlpack not work , when I visit dist tensor data after I wrote it already。
I use it as follow:
1、I build one dist tensor with th.ones() tensor
2、I update some parts of this dist tensor with random tensor
3、then I found ,my update part in my current machine,can‘t visit by others machine, it return zhe old data (th.ones())
4、I think this is dlpack not work bug. so I commented out some code in dgl as follow :
1: kvstore.py push method local udf update
2:kvstore.py pull method from local dlpack share memory
I use socket instead of it to fetch data。 and it work。
so is it a bug or something I used wrong ? need help