
Hi, I’m working on a recommendation problem on a heterograph with multiple node types. It’s roughly about users clicking on items. There are other interactions as well, but for simplicity I now focus on a simplified version. The approach is as follows.
- Define the graph with (‘user’, ‘click’, ‘item’) and (‘item’, ‘rev-click’, ‘user’) edge types
- Train a model
- optional linear input embed layer for users and items
- 3 layers of HeteroGraphConv wrapper around SAGEConv blocks, followed by ReLU and normalization
- Dotproductpredictor (for both positive and negative edges)
- max margin loss on the positive and negative scores
- Use cosine similarity search on users to get the most similar items
This kind of works (the model is learning), but I keep running into the same problem:
- Embeddings of users are separated from embeddings of items: they are clearly apart in embedding space, and as a result the similarity search produces sort of random results. Within the items space, I see that similar items are indeed close in space, but the users are just somewhere completely different. Between users and items, the means and standard deviations of each embedding feature are different.
See below image (mean +/- stddev for each of the 64 embedding features for users and collections (items))
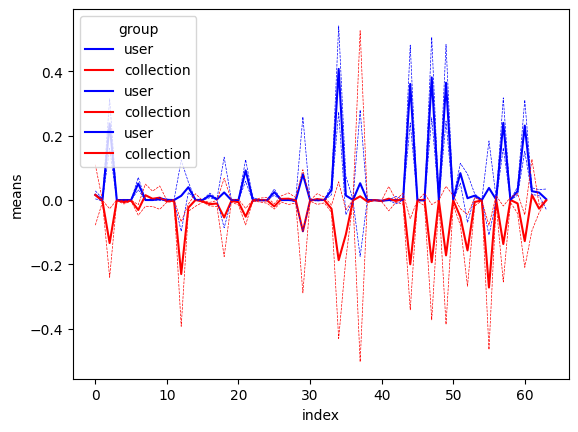
I’ve experimented with different options for normalization: with, without, batch normalization, in all layers except the last; use an extra input embedding layer before applying SAGEConv blocks… but all have the same result. Does this have to do with asymmetry in degree (users typically have 1 - 5 clicks, items have thousands)? What can be done about it?
- A second issue is that the loss during training is always of a different order per edge type: theloss for the reverse etypes always have a higher loss. What could be the cause of this?
Hope I’ve explained it well. I would be grateful for any tips.
Thanks, Robert