
Hello everyone! I do some research on sampling and DGL stream, I enable TensorAdaptor, set use_alternate_streams=True in DGL DataLoader and use GPU/CPU sampling with feature prefetch in NeighborSampler:
sampler = dgl.dataloading.NeighborSampler([4, 4], prefetch_node_feats=['feat'], prefetch_labels=['label'])
# GPU Sampling
graph=graph.to(device)
train_nids=train_nids.to(device)
Observation: DGL will create a non-default stream for every epoch(i.e. everytime the DGL DataLoader init). I trained 4 epochs, and the profiler shows 4 non-default stream:

Now I have some questions:
Q1: First, I found that after CPU sampling with prefetch, DGL do index select first and then do feature transfer :

No problem. Slice the features, then transfer.
However, after GPU sampling with prefetch, DGL do feature transfer first and then do index select:
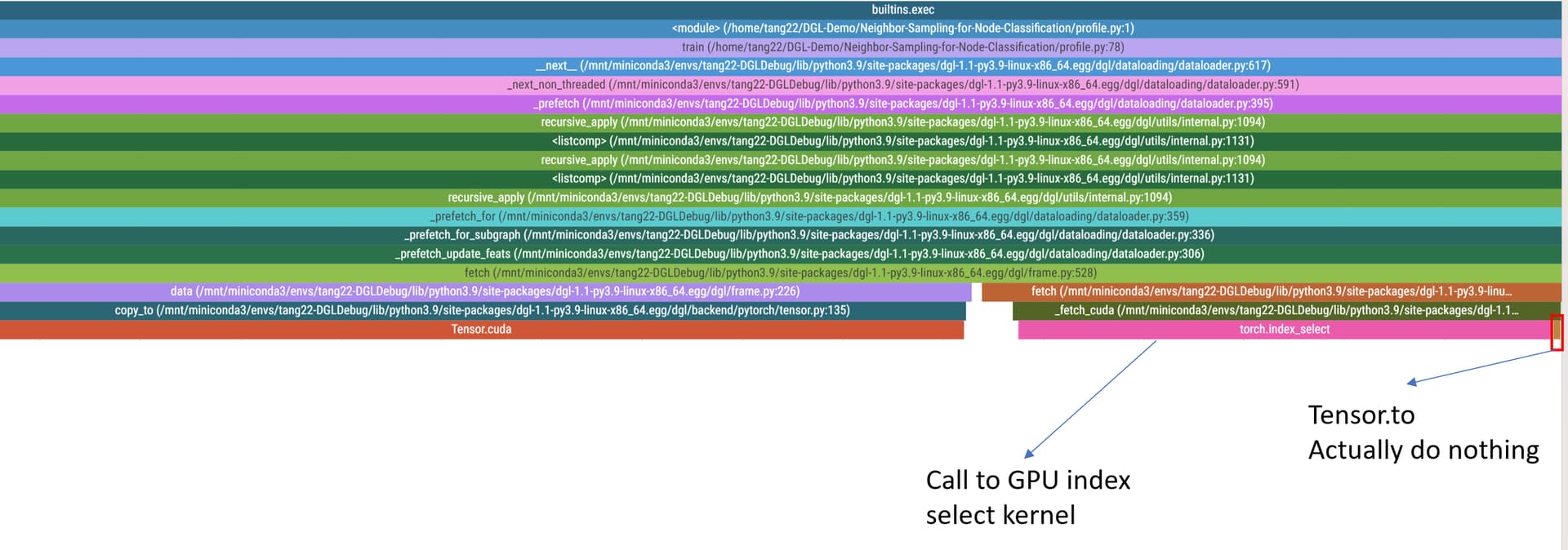
So why is there such a difference?
Q2: The documents says:
That’s true, when do GPU sampling, feature transfer(first) and index select kernel(then) are on a non-default stream 14. But I found that DGL now use pageable host memory for feature transfer:
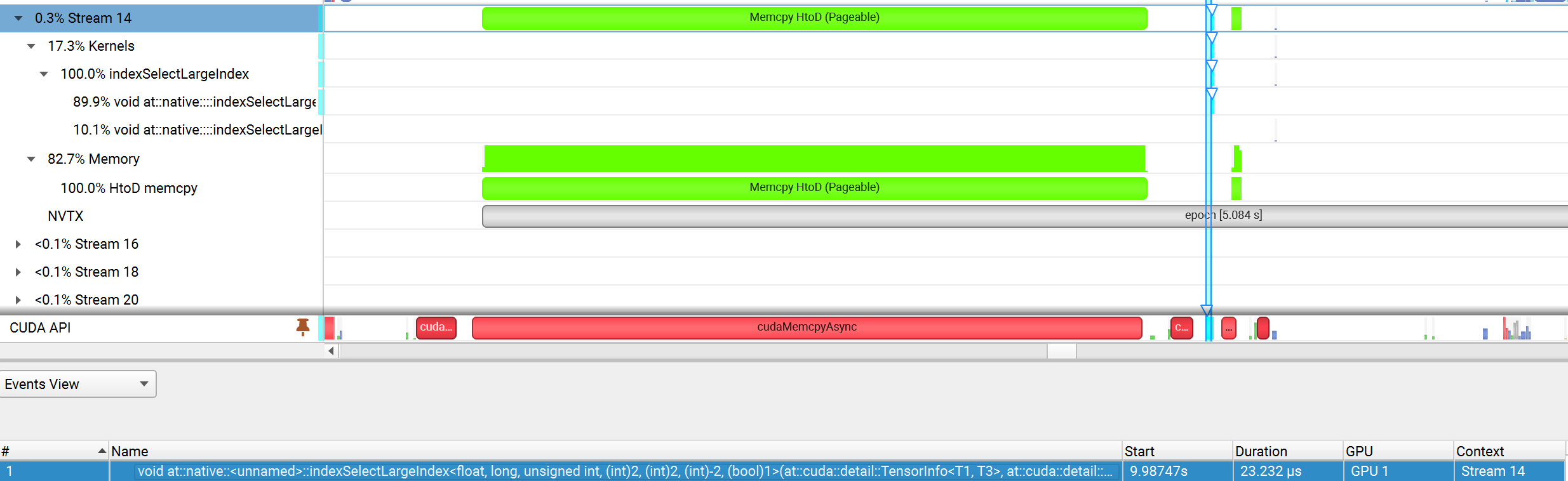
and it cannot be pinned maybe due to pin_prefetcher cannot be True when use GPU sampling:
As far as I know, pageable host memory causes asynchronous CUDA memcpy operations(e.g. cudaMemcpyAsync) to block and be executed synchronously. So what’s the point of using stream and cudaMemcpyAsync here? I think it will not do any good, because the usage of CUDA stream here overlap nothing.