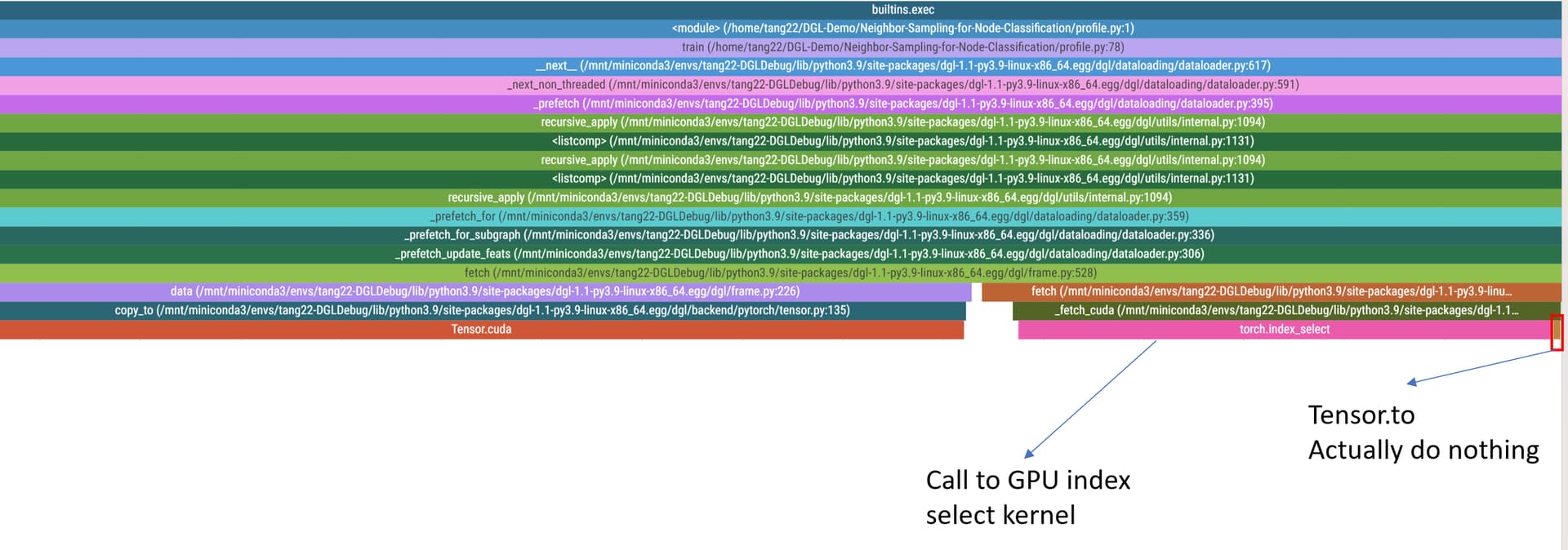
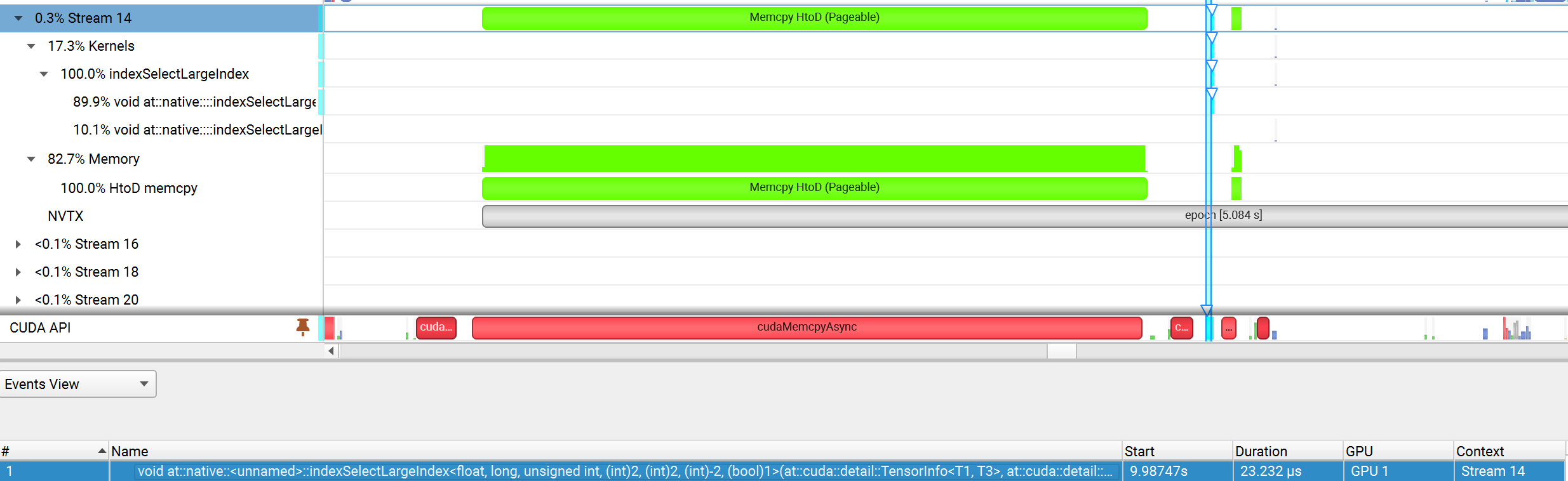
Hello everyone! I try to figure out GPU sampling algorithm in DGL, and I have some questions:
Q1: What’s the meaning of CSRMatrix data attribute?
I cannot even understand the comment
data index array. When is null, assume it is from 0 to NNZ - 1.
In my opinion, CSR or COO is used to represent sparse adjacent matrix, why are there numbers other than 0 and 1? I can see data[0] always be 12999 in my nsight eclipse during debug.
Q2: I think the code is trying to assign one block instead of one warp per row
because:
and BLOCK_SIZE=128, so TILE_SIZE=1. One block for one CSR row. Do I get it wrong?