Hi everyone. I would like to make sure of a simple thing.
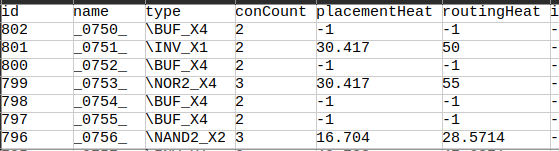
I have a dataset with multiple graphs, each of them looks like the following ( for the nodes file):
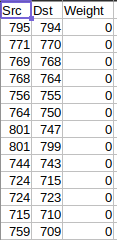
And an edges file like the following:
And some histograms for feature named type and the two labels:
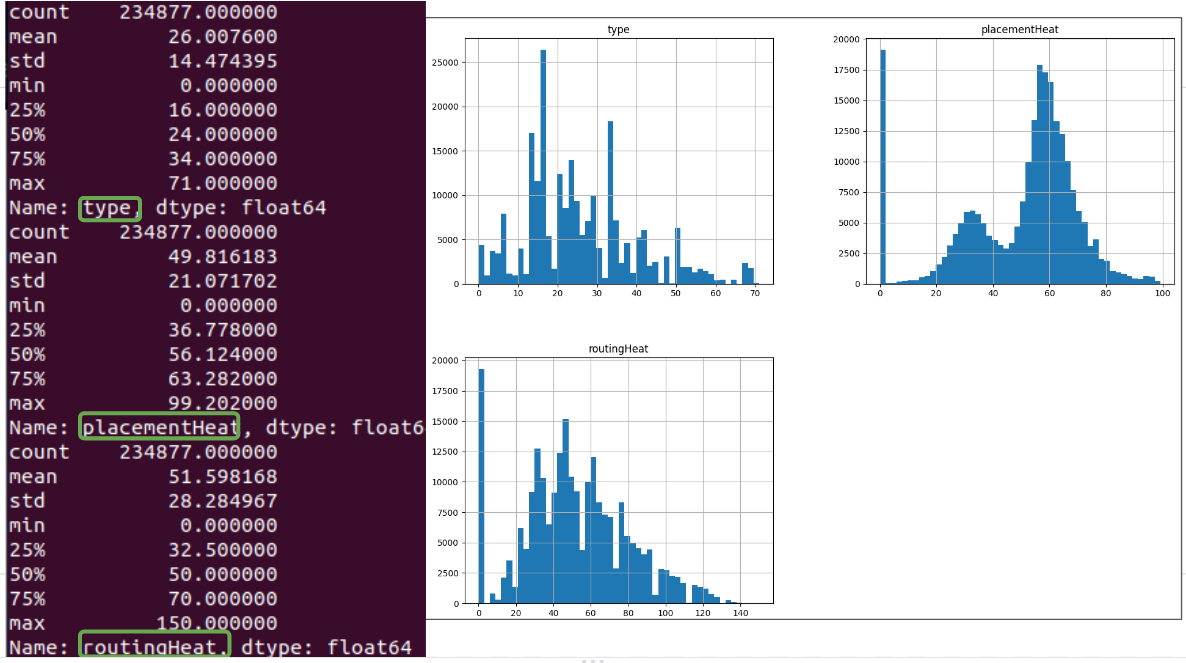
I will not use the name neither the id for training. Notice I have a categorical feature named ‘type’, when I apply an encoding to this column, it should take into account all the graphs right? For example ‘\INV_X1’ should be mapped to the same value in all other CSVs right?
Also, I would like to remove the rows with -1 and 0 values in the labels ( ‘placementHeat’ and ‘routingHeat’ ), but I don’t know how to proceed since this will produce missing ID nodes in the edges CSV… For this, I think I should try to apply a normalization to the labels since they have too many outliers with -1 and 0 values. This normalization should be applied in the same way with all the graphs in the dataset, correct?
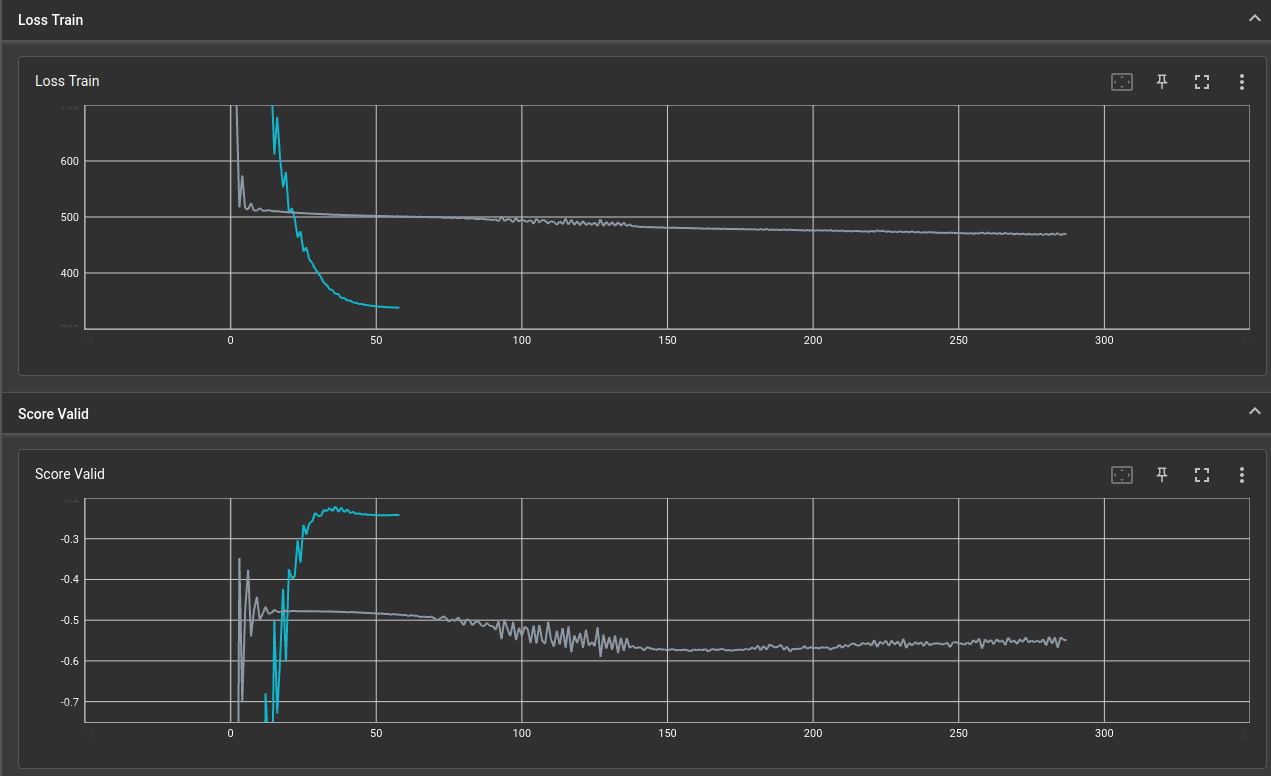
So far my implementation is reducing its loss value during training but its not really learning anything on its score.