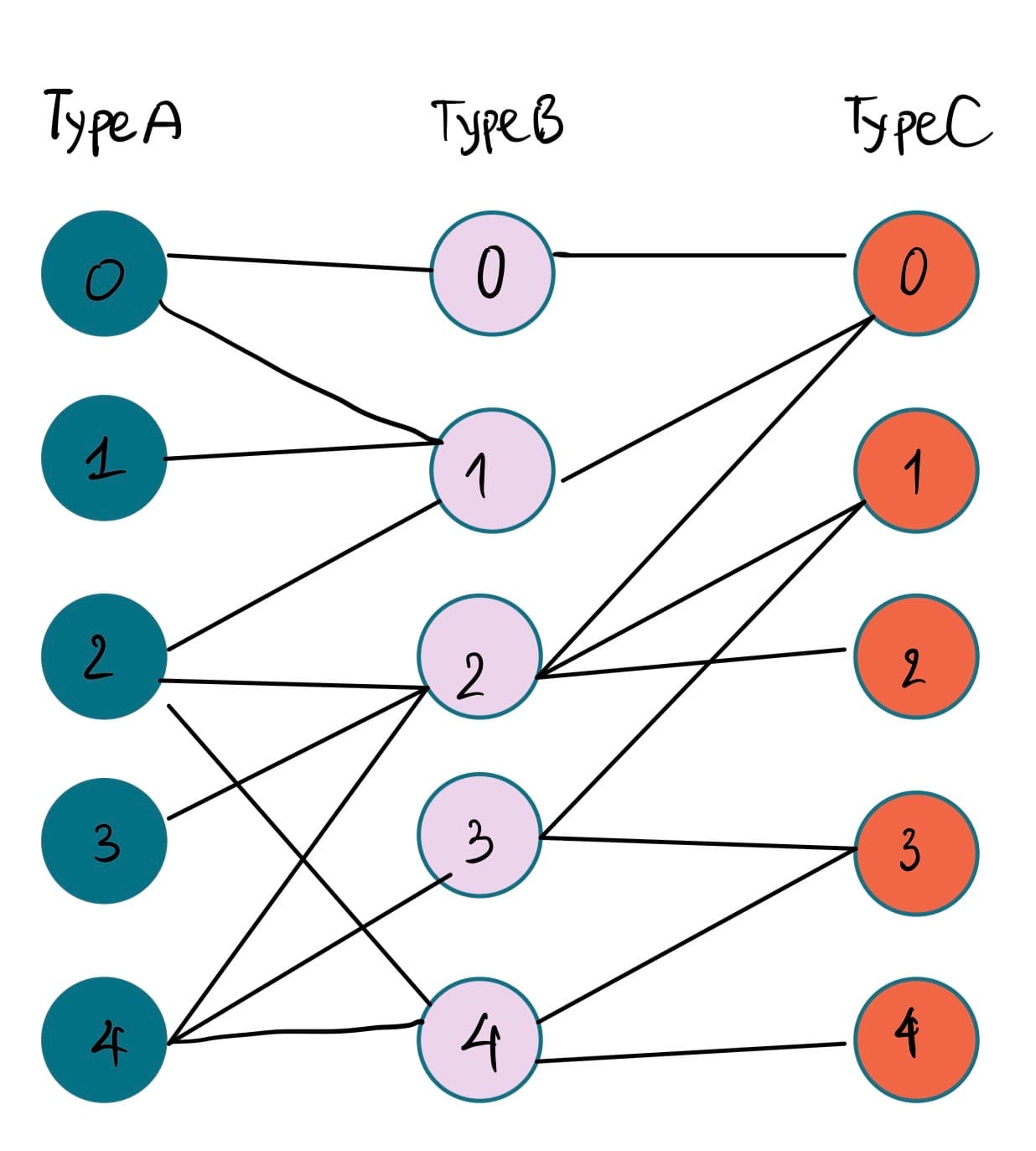
Hi there,
I am working on building custom dataset for a Heterogeneous graph to perform node classification for my thesis. The dataset contains 3 types of nodes (like (A, B, C) and edge happens between AC, BC as pic below.
I read in document that each row is considered as 1 node, however in my graph, for example, the nodes can have multiple labels (node type C). This make the output of num_nodes is always higher than num_edges.
To sum up, I am not sure how to build my custom dataset properly as the labels can be considered important feature of nodes (A or B)
Any suggestions are highly appreciate with great thanks
Have a nice day to all!