
Hi,
I have some questions about loading data.
As shown in the diagram below, my model is for node classification, and categorizes nodes into two types.
My dataset contains multiple graphs, each with different structures and about ten thousands of nodes. Only the nodes have features; the edges and graphs do not.
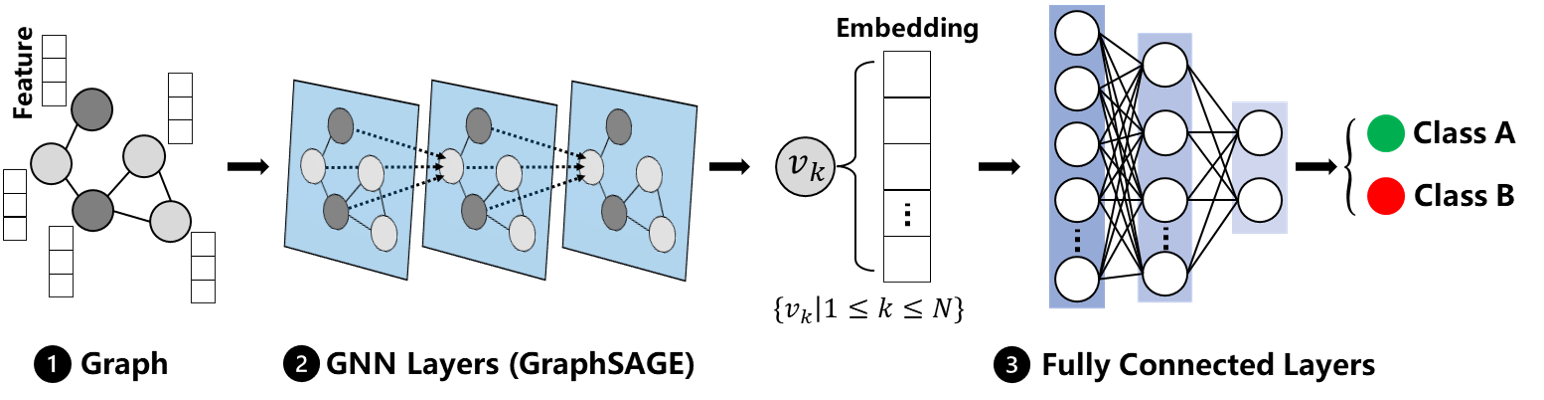
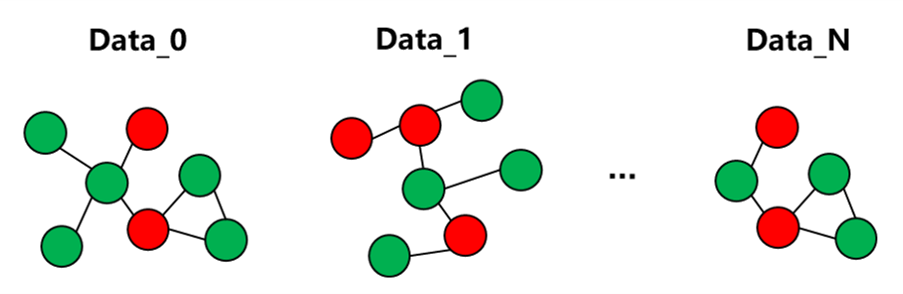
In the DGL 2.1.x user guide, chapter 4.6, I saw that data can be loaded from CSV files. Which way should I use?
- ‘Dataset of a single graph with features and labels’: Combine all graph into a single graph
- ‘Dataset of multiple graphs’
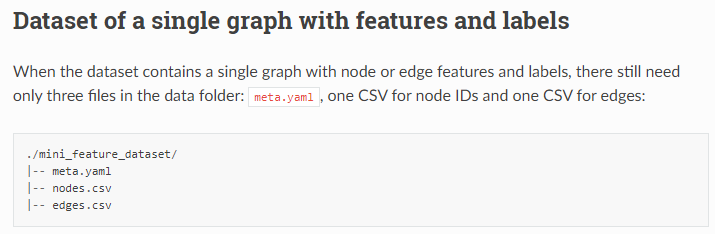

Does anyone have better suggestions?