
You give a very simple example of the dropout method with possibility p
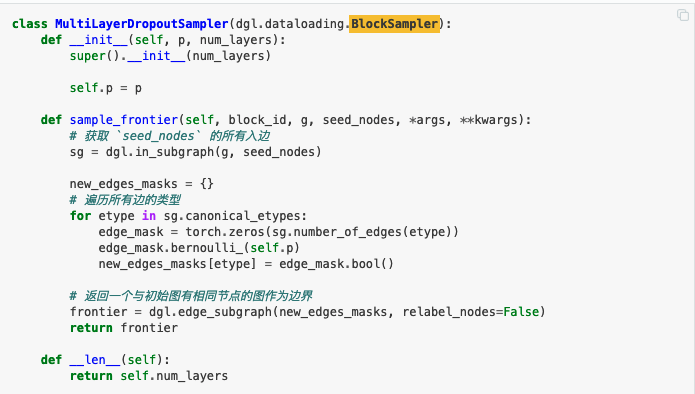
But in some cases, the sampler is more difficult. For example, I saw this paper NeuralSprase(ICML 2020) and wanted to implement it with DGL, but I am new to it. The key idea in this paper would be something like this:
- Calculate the score on each edge with MLP.

- For each node, do softmax on all its input edges.
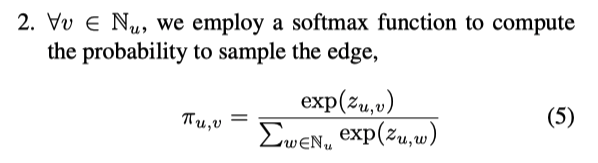
- For each node, samples k neighbors with gumbel softmax.

The process is list as below:

How do I implement this in an efficient way? I think there are many difficulties.
- Could I give more parameters to function sample_frontier? Which codes should i revise in some other place??
- How do I conduct softmax operations in an efficient way? The simple example above only masks edges with p, but i want to sample edges for each node with its probability distribution on its neighbors as input. It seems very time-consuming by traversing each node one by one.
- How do the network in the sampler be trained with the loss function.
Thank you for your continued help and support and look forward to your reply!!!