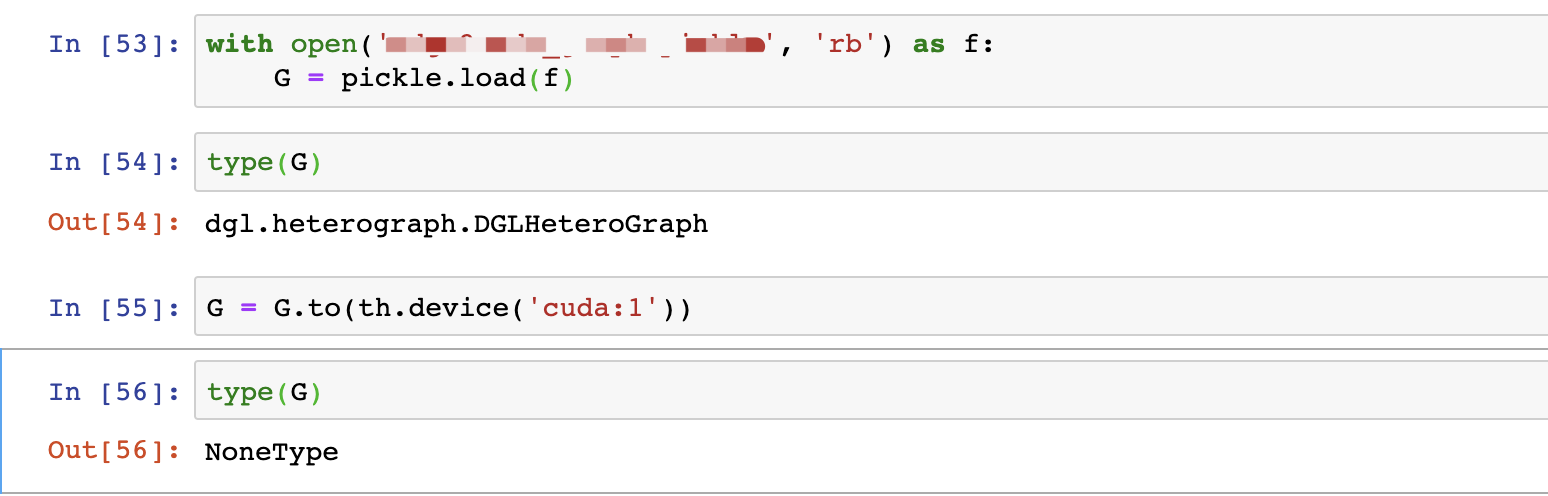
If I want to put a graph on a GPU (say “cuda:0”), how can I do that? I’m looking for the equivalent of a torch.tensor.to(“cuda:0”) operation. I would like to do this because I have a large dataset of small graphs and I’m loading them with a DataLoader and batching them together as shown in the " Batched Graph Classification With DGL" tutorial. I do not want to put the entire dataset on the GPU (because it’s too big), but I do want to send the graph batches to the GPU when I am doing training and inference.
Any help would be appreciated.