
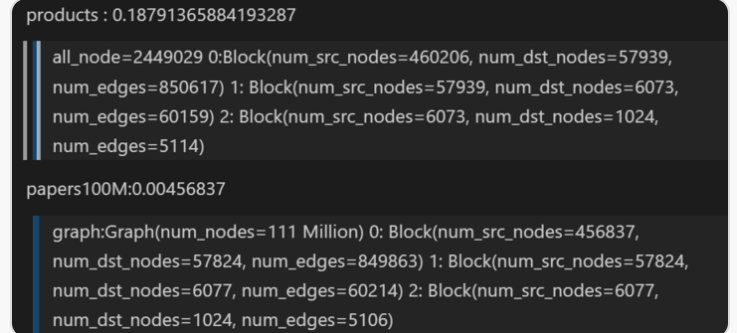
Although this problem may not be easy to solve, but I still hope that someone can help(or give a hint) me with this answer. The question is why the sample process of ogbn-products is much longer than ogbn-papers100M(about 5 times). I only change the dataset name and here is my code GNN_acceleration/profile_manual_pin_CPUGPU.py at main · yichuan520030910320/GNN_acceleration · GitHub I will give my result the sample process of ogbn-products takes 100ms or so but the sample process of ogbn-papers100m takes 23ms but the sampled node size is nearly the same between two dataset.
I use tensorboard profile and find the main difference between them is the fuction of
subgidx = _CAPI_DGLSampleNeighbors(g._graph, nodes_all_types, fanout_array, edge_dir, prob_arrays, excluded_edges_all_t, replace) in dgl/dataloading/neighbor_sampler.py but the problem is papers100M is much bigger than products and I am confused about this issue.
you can run python profile_manual_pin_CPUGPU.py --dataset ogbn-products or python profile_manual_pin_CPUGPU.py --dataset ogbn-papers100M to reproduce the result
Thanks in advance if some one can help me!