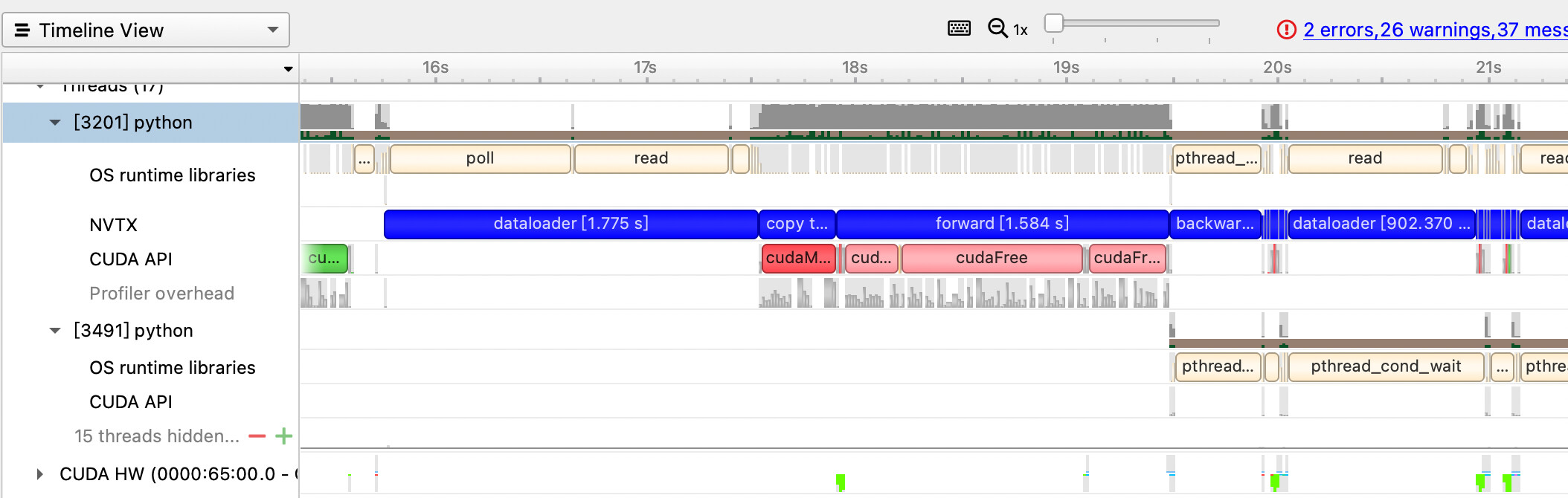
Hello everyone.
I am trying to follow the distributed training using DGL here: dgl/examples/pytorch/graphsage at master · dmlc/dgl · GitHub. And I use pytorch profiler to monitor the activity of CPU and GPU.
It looks like that:
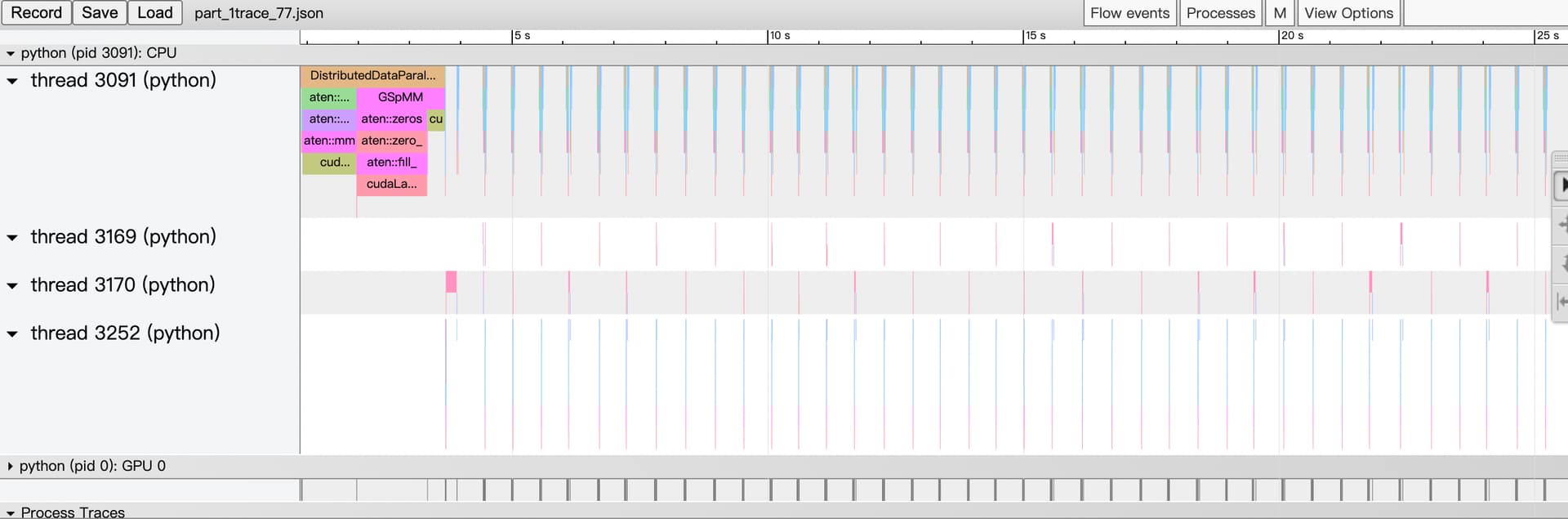
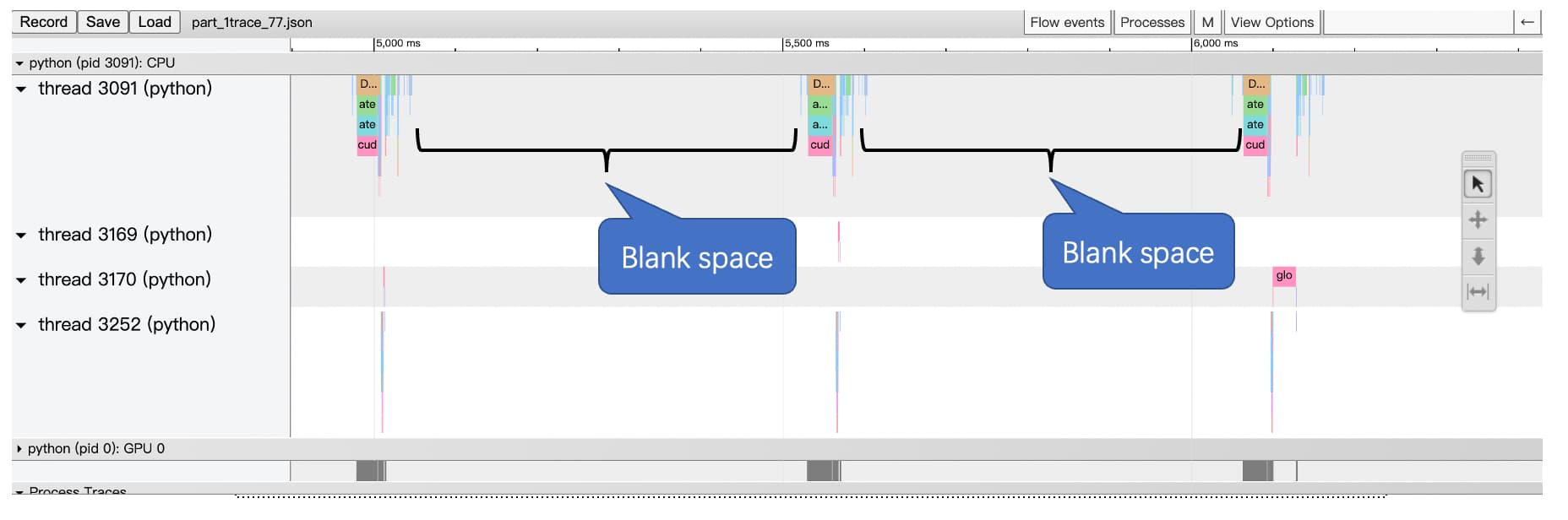
I wonder what those blank spaces between each iteration mean. Is it a normal behaviour or something can be wrong inside my implementation?
I am using pytorch in it’s GPU-version in an own conda environment and the communication backend is ‘gloo’. There are two machines in the cluster and each machine has an RTX3080. Here the packages that are installed in my conda environment:

Can anybody help me with this?
Thank you in advance,
Yaqi