Thanks so much @mufeli!
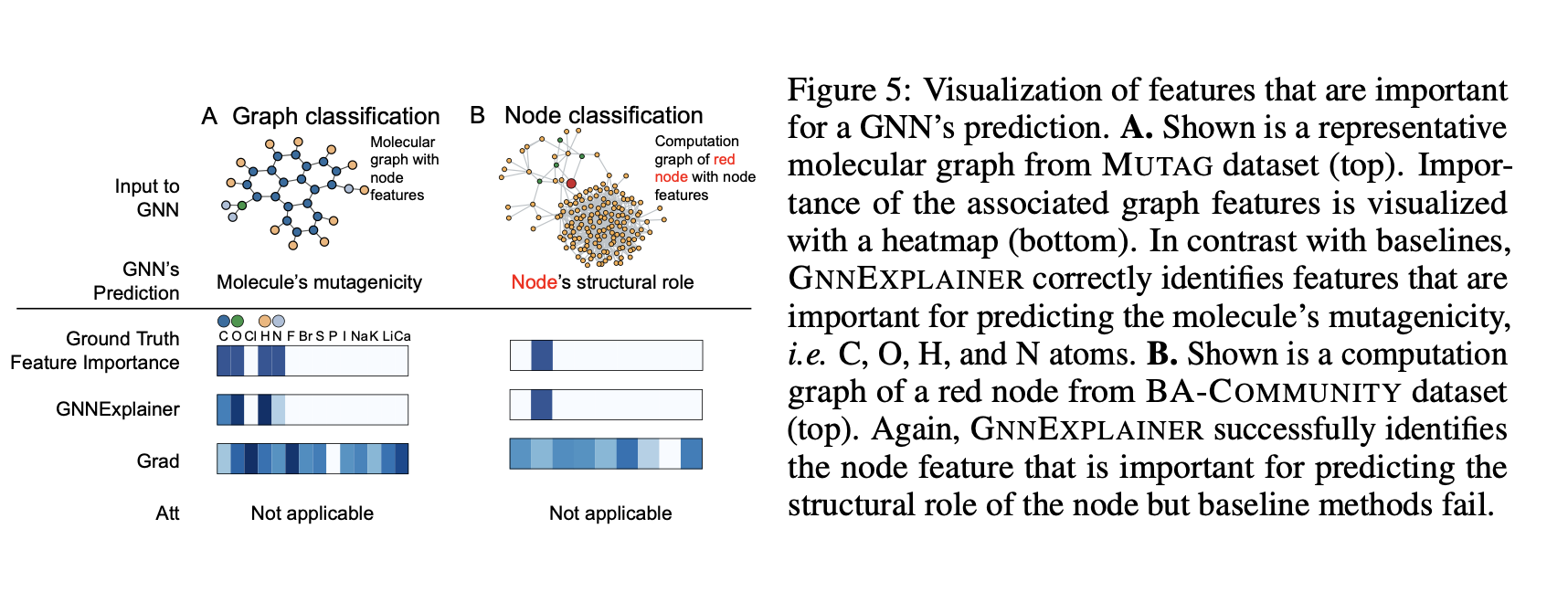
GNNExplainer aims at identifying a subgraph and a subset of the node features that allow approximating the original model predictions. In this way, it does use labels, but the labels are the predictions of a GNN to explain.
This makes a lot of sense, thanks for explaining it!
Did you also change the number of GNN layers when changing the number of hops?
With this do you refer to the layers in the GNN model? If yes, then yes I did change them 
You can also try adding fake or trivial node features and see if GNNExplainer manages to assign low importance scores to them.
I have been investigating this a little bit further both with my data and with the one used in the example (my data has 19 node features and the example one has 7).
- I first tried making zeros all the features except a few in my own data:
When I use the correct features without making anything zero yet I get the following for a particular graph:
feat_mask = tensor([0.2796, 0.2358, 0.2982, 0.2932, 0.2907, 0.2584, 0.2548, 0.2890, 0.2668,
0.2450, 0.2933, 0.2431, 0.2656, 0.2756, 0.2456, 0.2537, 0.2591, 0.2613,
0.2796])
When I zero out some of the features, I still get very similar results:
A = np.zeros_like(g.ndata['h_n'].detach().numpy())
A[:,5]=g.ndata['h_n'].detach().numpy()[:,5]
A[:,10]=g.ndata['h_n'].detach().numpy()[:,10]
A[:,18]=g.ndata['h_n'].detach().numpy()[:,18]
features = torch.tensor(A)
feat_mask, edge_mask = explainer.explain_graph(g, features)
feat_mask = tensor([0.2763, 0.2770, 0.2616, 0.2513, 0.2592, 0.2937, 0.2610, 0.2516, 0.2467,
0.2352, 0.2506, 0.2497, 0.2800, 0.2693, 0.2958, 0.2284, 0.2671, 0.3004,
0.2791])
- I tried something similar in the data for the example:
explainer = GNNExplainer(model, num_hops=1,lr = 0.01)
g, _ = data[0]
features = g.ndata['attr']
feat_mask, edge_mask = explainer.explain_graph(g, features)
feat_mask = tensor([0.2844, 0.2770, 0.2995, 0.2504, 0.2628, 0.2609, 0.2833])
and when zeroing some of the features out:
A = np.zeros_like(g.ndata['attr'].detach().numpy())
A[:,5]=g.ndata['attr'].detach().numpy()[:,5]
A[:,6]=g.ndata['attr'].detach().numpy()[:,6]
A[:,3]=g.ndata['attr'].detach().numpy()[:,3]
features = torch.tensor(A)
feat_mask, edge_mask = explainer.explain_graph(g, features)
feat_mask = tensor([0.2777, 0.2612, 0.2789, 0.2848, 0.2802, 0.2496, 0.3019])
Is this normal? I was trying to upload an image showing the histogram of the feature importances in all the nodes but I can’t for some reason. They show what I mentioned yesterday, all the importances were between 0.2 and 0.3 with very similar means.
It must consider edge weights with an optional argument eweight , otherwise the edge importance scores were just randomly initialized from a normal distribution.
Lastly, for this I have two questions. This is a pre-trained model that I have the weights saved for. Can I just add something the below? (It is based on the provided example):
class Classifier_gen(nn.Module):
def __init__(self, in_dim, hidden_dim_graph,hidden_dim1,n_classes,dropout,num_layers,pooling):
super(Classifier_gen, self).__init__()
if num_layers ==1:
self.conv1 = GraphConv(in_dim, hidden_dim1)
if num_layers==2:
self.conv1 = GraphConv(in_dim, hidden_dim_graph)
self.conv2 = GraphConv(hidden_dim_graph, hidden_dim1)
if pooling == 'att':
pooling_gate_nn = nn.Linear(hidden_dim1, 1)
self.pooling = GlobalAttentionPooling(pooling_gate_nn)
self.classify = nn.Sequential(nn.Linear(hidden_dim1,hidden_dim1),nn.Dropout(dropout))
self.classify2 = nn.Sequential(nn.Linear(hidden_dim1, n_classes),nn.Dropout(dropout))
self.out_act = nn.Sigmoid()
self.num_layers = num_layers
self.mypooling = pooling
def forward(self, graph,feat, eweight=None):
# Use node degree as the initial node feature. For undirected graphs, the in-degree
# is the same as the out_degree.
# Perform graph convolution and activation function.
# Calculate graph representation by averaging all the node representations.
num_layers = self.num_layers
pooling = self.mypooling
h = feat.float()
# Perform graph convolution and activation function.
h = F.relu(self.conv1(graph, h))
if eweight is None:
graph.update_all(fn.copy_u('h', 'm'), fn.sum('m', 'h'))
else:
graph.edata['w'] = eweight
graph.update_all(fn.u_mul_e('h', 'w', 'm'), fn.sum('m', 'h'))
h = F.relu(self.conv2(graph, h))
if eweight is None:
graph.update_all(fn.copy_u('h', 'm'), fn.sum('m', 'h'))
else:
graph.edata['w'] = eweight
graph.update_all(fn.u_mul_e('h', 'w', 'm'), fn.sum('m', 'h'))
graph.ndata['h'] = h
# Calculate graph representation by averaging all the node representations.
#hg = dgl.mean_nodes(g, 'h')
if pooling == "max":
hg = dgl.max_nodes(graph, 'h')
elif pooling=="mean":
hg = dgl.mean_nodes(graph, 'h')
elif pooling == "sum":
hg = dgl.sum_nodes(graph, 'h')
elif pooling =='att':
# Calculate graph representation by averaging all the node representations.
hg = self.pooling(graph,h)
a2=self.classify(hg)
a3=self.classify2(a2)
return self.out_act(a3)
It is giving me an error
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-71-dd81e9fa2c48> in <module>()
1 g = trainsetMB[1][0]
2 features = g.ndata['h_n']
----> 3 feat_mask, edge_mask = explainer.explain_graph(g, features)
5 frames
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py in linear(input, weight, bias)
1846 if has_torch_function_variadic(input, weight, bias):
1847 return handle_torch_function(linear, (input, weight, bias), input, weight, bias=bias)
-> 1848 return torch._C._nn.linear(input, weight, bias)
1849
1850
RuntimeError: mat1 and mat2 shapes cannot be multiplied (907x19 and 7x2)
And I don’t know what is really happening.
So sorry for my very-long comment and many thanks for all your help!